Just Remove Dialogue? Why Music & Effects Separation Makes or Breaks Dubbing Quality
Just Remove Dialogue? Why Music & Effects Separation Makes or Breaks Dubbing Quality
Disclosure: It would be helpful to first understand what DME separation is and what role it plays before reading this blog.
➡️ [Why Global OTT Platforms Choose Gaudio Lab: The Gold Standard in AI DME Separation]
In this blog post, we'd like to discuss the role and importance of M&E in the process of AI dubbing for content, as well as the challenges that remain.
Why the M&E Track Is More Than a Byproduct of Dialogue Removal
In dubbing workflows for localization, the M&E (Music & Effects) track is often misunderstood as simply "what's left after removing dialogue." In practice, however, it serves a much more critical role. The M&E track of the audio becomes the foundation onto which a new language is layered, and therefore must function as a clean, natural background — one that is immediately mix-ready. This is precisely what distinguishes M&E separation from general-purpose audio source separation (stem separation) or dialogue extraction tasks.
-
Dialogue extraction focuses on recovering speech signals with sufficient intelligibility. In many cases, some degree of background audio leakage is acceptable as long as the extracted dialogue remains clear and usable.
-
M&E separation imposes the opposite constraint. The objective is to remove dialogue* entirely, without leaving unnecessary traces, while preserving the naturalness of everything that remains. Once new voice tracks are layered on top, even small remnants of the original dialogue quickly become noticeable in the final mix.
When performing dialogue removal from a master file, you can observe cases where the dialogue is either over-separated or under-separated.
*Here, "dialogue" can be interpreted more broadly. It includes not only clean speech, but also emotionally intense vocalizations (e.g., shouting, sobbing), intentionally distorted dialogue (e.g., vocoder effects), reverberant dialogue with long tails, and mixtures of multiple speakers such as crowd voices. These are the very cases where the difficulty of separation increases significantly.
We tested M&E separation on the video below using technologies from several companies in the field. Here's what we found: separating clean dialogue is the easy part. But the content we actually consume often has voices mixed with sound effects or heavily distorted. Being able to cleanly separate even these challenging voices is what it truly means to be ready for dubbing.
[Original]
[AudioShake]
[Moises]
In this case, you can see that emotional speech and non-dialogue vocalizations — such as laughter and breathing — were not removed and ended up remaining in the M&E track. These residual components would cause interference once new dubbed voices are layered on top.
[GAUDIO]
Why M&E Separation Is So Challenging When Working with Real Audio
The difference between what is commonly called "stem separation" and M&E separation becomes even clearer when processing real-world audio. Dialogue in content often overlaps with music and sound effects both spectrally and temporally. Reverberation spreads vocal elements across time, making them difficult to localize and remove cleanly. On top of that, many signals that are not strictly dialogue — such as laughter, crying, or breathing — share similar acoustic characteristics with speech, vocals, or even instruments. Removing dialogue introduces gaps in the signal, and if these are not handled properly, they manifest as unnatural artifacts or discontinuities.
For these reasons, M&E separation should not be treated as a simple subtraction problem. It is more accurately described as a process that combines "removal with perceptual reconstruction." The result after dialogue removal must sound natural — it should never sound like a degraded residual of the original mix.
How Gaudio Lab Does It: Usability-First M&E Separation
Gaudio Lab's research team has recently been closely examining M&E separation with an emphasis on usability in actual dubbing pipelines. One important design decision is how to treat dialogue-like vocalizations (such as laughter, crying, breathing, and certain vocal components). Rather than mistakenly preserving them as background, the system is designed to classify them as dialogue and remove them accordingly. This is particularly emphasized in our M&E v2 configuration (API), where the primary goal is to provide a clean, interference-free background audio for dubbing.
At the same time, careful attention is given to preserving the continuity — the naturalness — of the remaining signal. Spatial characteristics, reverberation, and ambient textures are maintained so that the output remains coherent over time. Minimizing perceptual artifacts and spectral gaps introduced during dialogue removal is critical. This is also a key point of differentiation from the level of M&E separation the industry has been doing so far. Traditionally, residual sounds and unnatural textures would remain, often requiring additional post-processing.
The objective is not limited to achieving strong separation metrics. It is about producing outputs that can be directly used in downstream mixing without further correction. In this sense, Gaudio Lab views usability as the primary evaluation criterion.
Validated Performance and Production Deployment
Gaudio Lab has recently validated this usability-focused approach across a range of real-world content. The results confirm strong performance in suppressing dialogue audio, maintaining perceptual continuity, and maximizing practical usability.
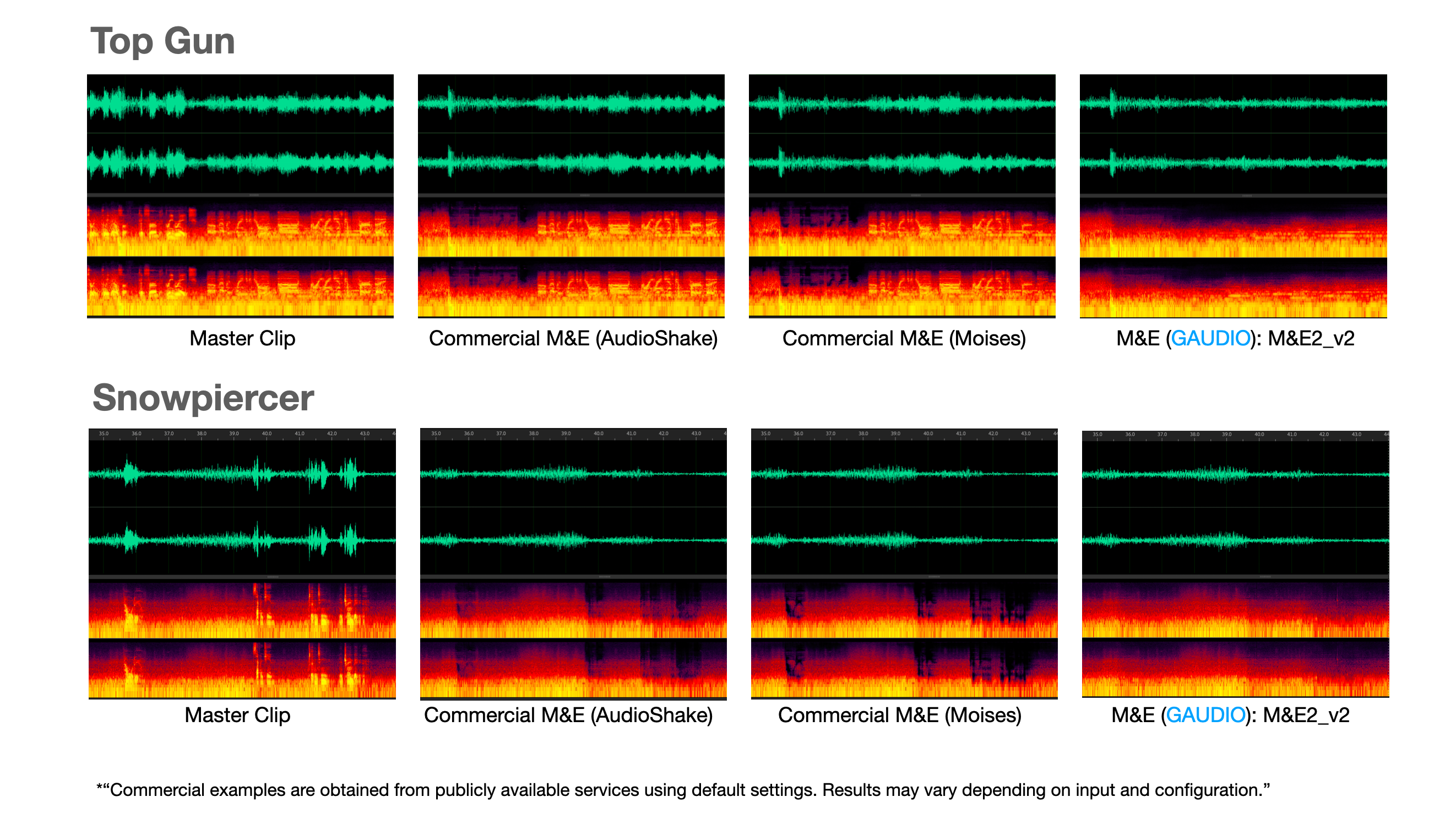
We've taken spectrogram comparisons of M&E separated from master files. Among samples that are notoriously difficult for AI separation, we tested excerpts from the internationally well-known Top Gun and Snowpiercer. You can observe issues like residual sounds remaining after M&E separation, or over-separation causing audible artifacts. (Can you see how clean and clear Gaudio Lab's technology is? :) ) Try Gaudio’s M&E2 v2 via an API.
This technology has now moved from the lab into production environments. It is being delivered to Gaudio Lab's clients and is integrated into the GSP platform, where it is actively used in production-quality dubbing and localization workflows.
Wrap-Up
To summarize: dialogue extraction and M&E separation may appear similar at a high level. However, they differ fundamentally in both their objectives and constraints. M&E separation requires not only removing a target signal, but also preserving — and when necessary, reconstructing — the perceptual structure of the remaining audio, so that new layers such as multilingual dubbing can be built on top. Obsessing over even the most subtle differences to create the best possible listening experience — that is exactly what Gaudio Lab's research team is dedicated to.

Our audio technologies support various devices and platforms.
