[Q&A] 8 Frequently Asked Questions About AI Transcription (STT)
[Q&A] 8 Frequently Asked Questions About AI Transcription (STT)
Introducing the 8 key considerations for AI transcription, the first step in AI dubbing
Various tools are emerging to improve quality and save time in the content localization process. We would like to explain AI Transcription, which is the first step for content localization via AI Dubbing. Here are 8 tips covering the most frequently asked questions and critical considerations when proceeding with AI transcription for AI dubbing.
When reviewing AI dubbing, the first stage you encounter is Transcription. It may seem like a simple task of converting sound to text (STT), but it is the most crucial area because the quality of this first step determines the quality of the final dubbing. For example, if the intention or context of the original text is not considered or is transcribed uniquely, errors can occur that make the dubbing sound unnatural.
Q1. What is Transcription? Is it different from Subtitles or Meeting Minutes?
Simply put, transcription is the process of converting all spoken content into text. The table below summarizes the differences between Transcription, Subtitles, and Meeting Minutes.
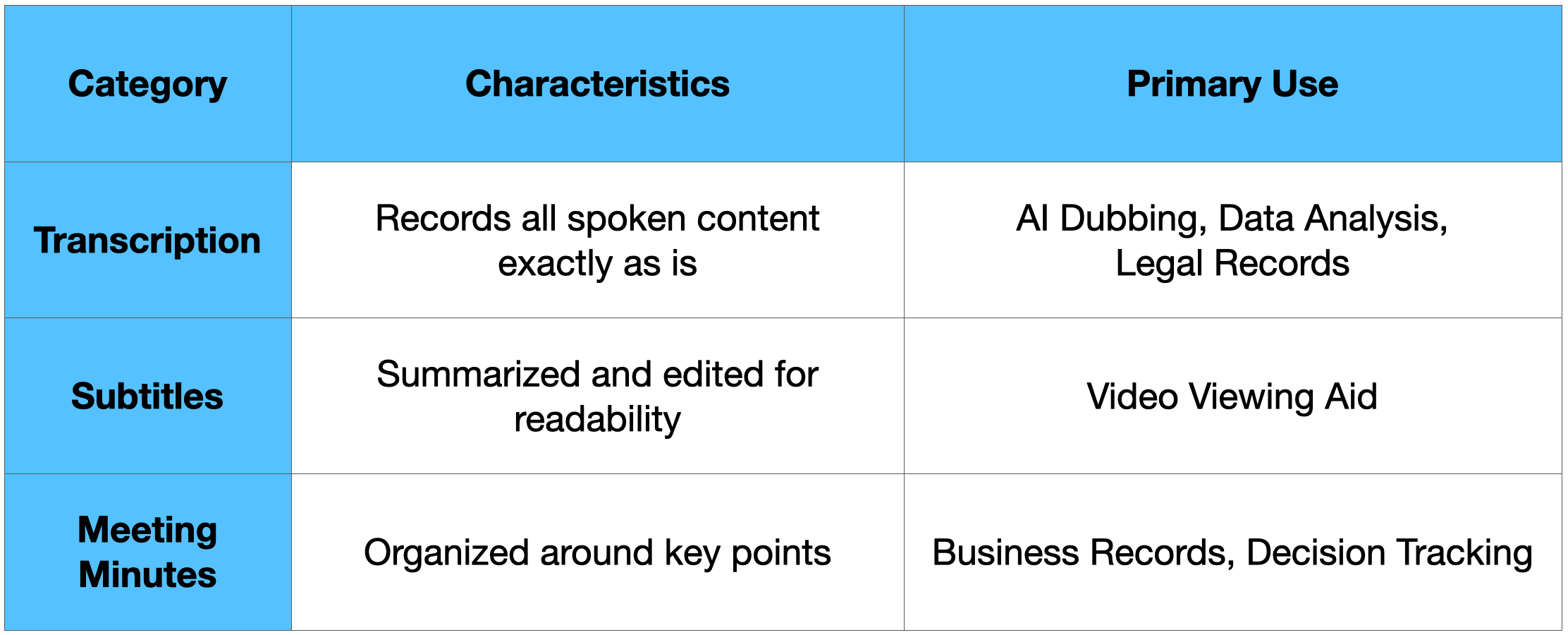
Transcription for dubbing must capture not only the speaker's basic voice but also their breathing, tone, and even emotions. Therefore, it is fundamental to transcribe every single word exactly as recorded, rather than simply summarizing.
However, there is one direction further to go. It must not just be a transfer of text; it must capture all information so that it can be dubbed as is.
"True AI Transcription must analyze the context of the video and extract situational information necessary for dubbing."
Since Gaudio Lab AI Transcription is specialized for dubbing, it can produce 'ready-to-use transcription' results as shown below:
Gaudio Lab’s Dubbing-Specialized AI Transcription Results:
-
Character-based Speaker Identification: Distinguishes speakers by their actual character names in the work, not just Speaker 1 or 2.
-
SFX & Sound Effect Recording: Notes situations necessary for dubbing direction, such as crowd noises and background sounds.
-
Translation Phase Connection Info: Includes contextual information immediately usable in the next step.
-
Millisecond Timestamps: Precisely records the start/end time of each utterance.
-
Context Awareness: Grasps on-screen text, situations, and full context.
Q2. Is 'Verbatim Transcription' really essential for AI Dubbing?
Yes, it is.
For an AI Voice to properly bring out the emotion and tone of the original, the original utterance information must be captured without omission. Otherwise, low-quality AI dubbing is inevitable. Here is the difference between Verbatim Transcription and Edited Transcription.
Verbatim Transcription vs. Edited Transcription
-
Verbatim: "Uh, so... what I mean is" → Recorded exactly as spoken.
-
Edited: "My opinion is as follows" → Refined and recorded.
AI dubbing must capture the flow of the drama exactly. Therefore, it does not suit Edited Transcription. Natural voices and stories are created in dubbing only when the rhythm of speech, the protagonist's hesitation, and the emphasis of the context are reflected. While sentences refined through Edited Transcription may look clean, the original nuance disappears, making them unsuitable for AI dubbing and localization processes.
Q3. How reliable is the accuracy of AI Transcription?
Of course, it depends on the environment.
However, we record high accuracy: over 95% under good conditions and around 90% even in difficult environments.
The main causes for a drop in AI transcription accuracy are:
-
Loud background music or sound effects.
-
Recording in a space with reverberation (echo).
-
Low-quality compressed files (low bitrate).
General AI transcription services see a significant drop in accuracy in these environments. This is why specialized AI audio technology is needed.
The reason for Gaudio Lab's high transcription accuracy is our possession of world-class Source Separation technology. We increase transcription accuracy with separation technology that cleanly isolates Dialogue, Music, and Effects (DME).
Q4. How should I inspect the AI Transcription results?
Received the AI transcription results but don't know how to inspect them? Here is an inspection checklist!
Beyond obvious typo checks, you must carefully examine timestamp precision, sentence structure, and speaker separation. The quality of transcription dictates the quality of dubbing and significantly impacts efficiency across the entire localization workflow.
-
AI Transcription Quality Checklist:
☐ Are timecodes recorded precisely?
☐ Are spacing and punctuation natural?
☐ Are silent sections and speech sections accurately distinguished?
☐ Are utterances properly separated by speaker?
Furthermore, you need to inspect the deliverables with a multi-layered checklist structure.
If transcription quality is low, correction work increases geometrically during the translation and dubbing stages. To prevent this inefficiency, Gaudio Lab provides thoroughly inspected transcriptions based on precise timestamps and checklists, preventing redundant work and wasted time. Thanks to this, we can meticulously provide important information for AI transcription as follows:
-
Start/end times of each utterance are recorded in milliseconds.
-
Overlapping lines are all provided separately.
-
Proper nouns like brand names and person names are accurately marked to reduce translation errors.
-
Correction work in the translation/dubbing stages is minimized.
Q5. In multi-person conversations or meetings, can you distinguish who said what?
Yes, it is possible. This is made possible through 'Speaker Diarization' technology.
Speaker Diarization is the foundation for assigning each role and the corresponding voice in actual dubbing.
Why is Speaker Diarization important?
-
The correct AI Voice must be assigned to each speaker.
-
Identifying the speaker is essential for understanding the flow and context of the conversation.
-
Overlapping speech sections must be accurately separated.
Gaudio Lab goes beyond simple speaker separation to provide Character-Based Transcription ready for immediate use in dubbing. It shouldn't just be "how many people spoke," but accurately "who said what." This is called Character-Based Speaker Identification.
Character-Based Speaker Identification:
-
Distinguish by Real Character Names: Accurately distinguishes by the character names in the work, not Speaker 1, 2.
-
Perfect Separation of Overlap Sections: Records overlapping sections separately for each character.
-
Caster/Commentator Distinction: Distinguishes each speaker in sports broadcasts, podcasts, etc.
Since Gaudio Lab’s GSP (Gaudio Studio Pro) is linked with the post-transcription dubbing workflow, you can assign AI voices by character immediately and proceed with subsequent dubbing tasks within a unified platform. (Try it now!)
Q6. How long of a video can be transcribed? Can it handle videos over 1 hour?
Yes, it is possible. And the longer the video, the more critical it is that the timecodes do not drift.
The basic checklist when inspecting long-form transcription is:
-
Multi-Speaker Processing: Confirm that lines from many speakers are all processed individually.
-
Timecode Accuracy: Check that sync does not drift towards the end.
-
Quality Consistency: Confirm that identical quality is maintained from start to finish.
In corporate environments, 2-3 hour seminars and training videos are common, so the probability of encountering such cases is very high. Gaudio Lab has high satisfaction ratings in these areas for the long-form content we have processed.
Gaudio Lab's Long-Form Content Processing Track Record:
-
Movies: Extensive experience transcribing feature films over 2 hours.
-
Dramas: Accumulated experience processing continuous season-based episodes.
-
Sports/Broadcasts: Technology capable of transcribing long matches and live content.
Consistent quality is our greatest strength.
-
Consistent timecode accuracy with no exceptions throughout the entire video.
-
Maintenance of identical character names from start to finish.
-
Recording without omitting SFX and sound effects even in long-form content.
Q7. What file format are transcription results usually received in?
One-line conclusion: You can choose SRT, VTT, JSON, TXT, etc., depending on your usage.
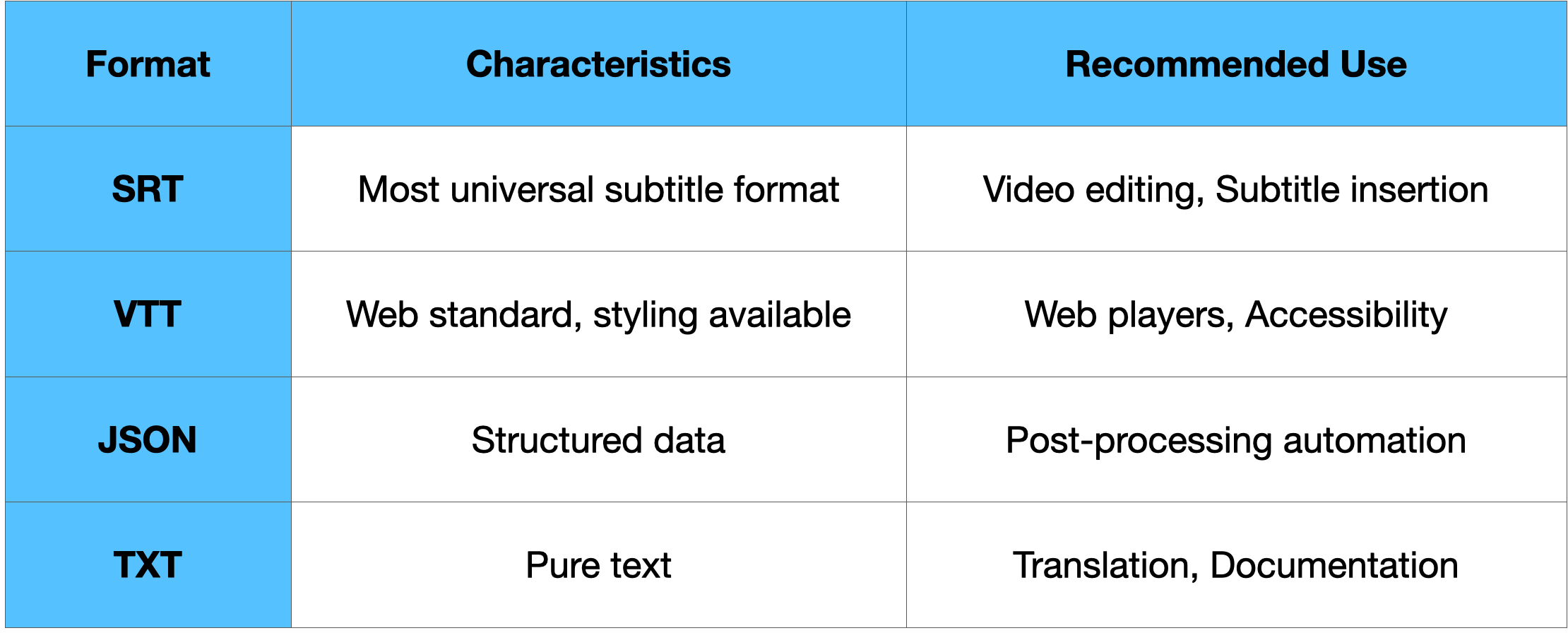
In particular, SRT/VTT formats containing timecodes are essential for dubbing workflows. Gaudio Lab goes a step further by offering a proprietary format specifically tailored for dubbing tasks.
Here is what the dubbing-specialized transcription format entails:
-
Character Info: Character names are included in each utterance, allowing for immediate use in selecting and assigning AI voices.
-
Translation Link Info: Provides data including contextual information required during the translation phase.
-
Precise Timestamp: Provides start/end times in milliseconds to ensure precise synchronization.
Furthermore, it is a "One-Tool" solution that supports workflow integration. Thanks to this, data seamlessly connects from the Translation → Dubbing stages. Since it can be used immediately in the next step without additional processing, it reduces costs and increases efficiency.
Q8. Are uploaded videos stored or used for AI training?
Gaudio Lab GSP does not use customer data for training. We do not use customer data for learning, and it is deleted after processing.
Here are the items you must verify during the video reproduction process:
-
File storage period and deletion policy.
-
Usage for AI model training.
-
Data encryption and transmission security.
Since some free services use uploaded data for training, it is essential to check their policies. Gaudio Lab does not use customer data for learning without explicit consent and applies strict security policies.
Security for B2B-dedicated services mainly implies the following:
-
Prohibition of Customer Data for AI Training: Data must be used only for service provision purposes.
-
NDA and Security Contracts: Must meet security levels required by global OTTs and broadcasters.
-
Project-Unit Data Management: Support for deletion upon customer request after processing is complete.
Gaudio Lab has earned the trust of the entertainment industry through numerous collaborations.
-
Extensive experience processing content such as movies, dramas, and sports.
-
Establishment of security management processes for pre-release content.
Transcription is Not the End, But the Beginning
As emphasized earlier, transcription is the blueprint for the entire content localization and distribution process, including AI dubbing. No matter how excellent the AI Voice used is, if context and emotion are missing from the transcription stage, the result is bound to be awkward.
Gaudio Lab's Audio AI technology, which has maintained the industry's highest level for over 10 years, saves customers time by providing transcription that captures not just simple text conversion, but video context and speaker intent.
This is why customers seeking content localization solutions choose Gaudio Lab:
-
Transcription Considered for Dubbing:
-
Transcription that supplements the limitations of standard AI transcription.
-
Includes character names, SFX, and sound effects.
-
Minimizes correction work in translation and dubbing stages.
-
-
Content Understanding-Based Transcription:
-
Reflects content context beyond Voice-to-Text conversion.
-
Accurately notates sounds as heard and distinguishes speakers according to character relationships and situations.
-
-
One-Stop Pipeline:
-
Seamless GSP workflow from Transcription → Translation → Dubbing.
-
Comfortable design keeping dubbing in mind from the very start.
-
Start the first step of successful global localization with Gaudio Lab!
We'll be back next time with an introduction to Gaudio Lab's AI Translation.


Our audio technologies support various devices and platforms.
