Why Global OTT Platforms Choose Gaudio Lab: The Gold Standard in AI DME Separation
Why Global OTT Platforms Choose Gaudio Lab: The Gold Standard in AI DME Separation
The Premium Benchmark for Source Separation, Crafted by AI Experts Who Truly Understand Sound
"The difference between AI that merely calculates waveforms and AI that deeply understands the context of sound is night and day."
There is a clear reason why global OTT platforms and premium content studios choose Gaudio Lab for their most demanding projects. We go beyond performance proven only by numbers; we are an AI company built by 'audio experts' who prioritize the actual texture, integrity, and perceptual quality of the sound you hear.
Today, we’re taking you behind the scenes of Gaudio Lab’s DME Separation—an industry-leading technology that breathes new life into content by precisely isolating Dialogue (D), Music (M), and Effects (E) from master audio—and the proprietary GSEP-SHQ architecture that makes it all possible.
1. What is DME Separation?
The Three Pillars of Audio: D, M, and E
Audio for video content is generally composed of three core elements:
-
Dialogue (D): Character voices and spoken content.
-
Music (M): Background music (BGM), insert songs, and theme tracks.
-
Effects (E): Foley, ambience, sound effects (SFX), and everything else outside of D and M.
DME Separation is the technology used to cleanly extract these three elements into individual tracks from a single, flattened "Full Mix" or Master audio file. In the industry, this is often referred to as 'M&E Separation' (separating Dialogue from Music/Effects), and it falls under the broader categories of 'Source Separation' or 'Stem Separation.'
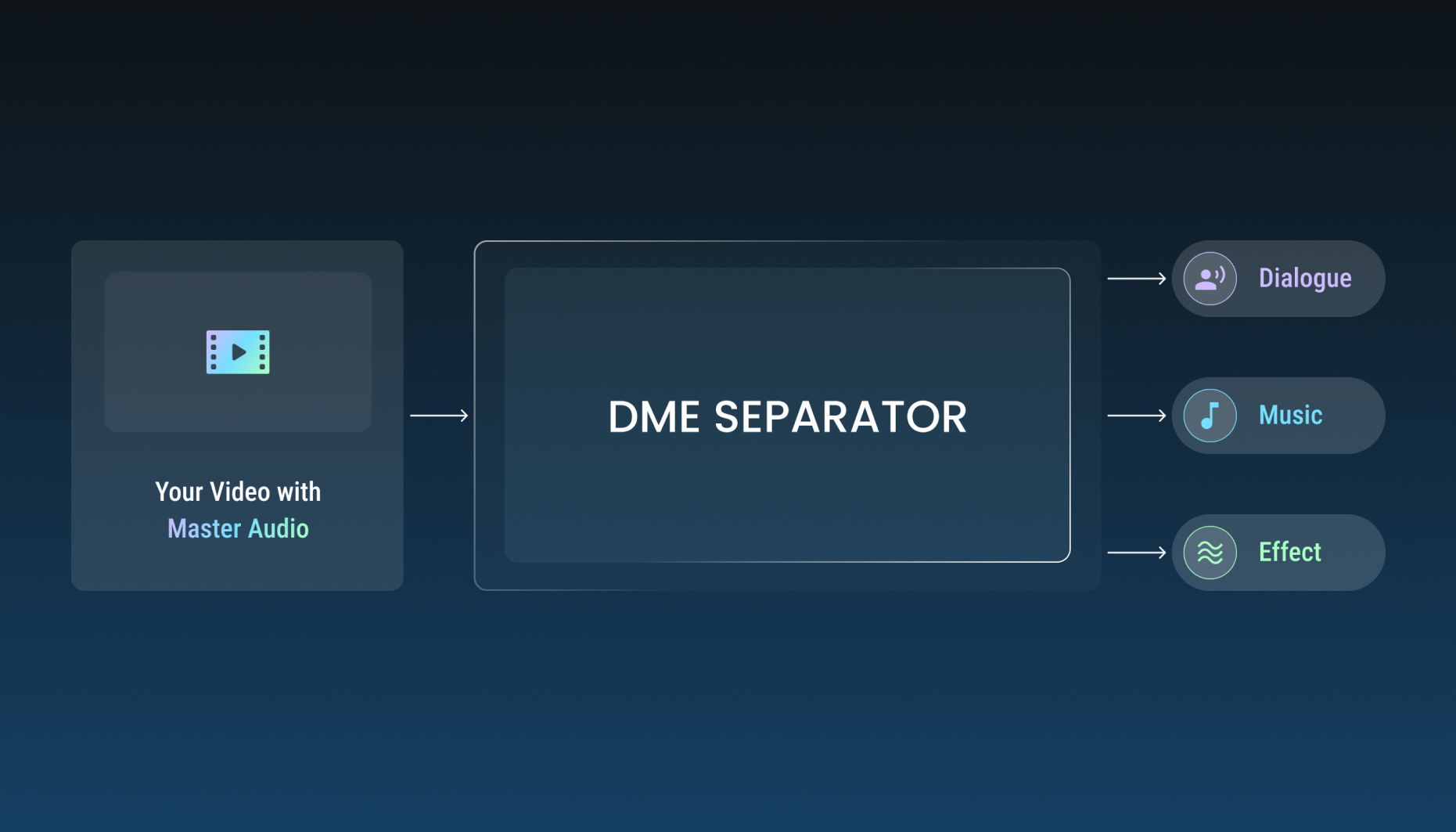
[Gaudio Lab's DME Separation]
Who Needs It and Why?
In fast-paced production environments, individual stem tracks are often lost or never archived due to tight schedules. DME Separation becomes a "game-changer" for post-production in the following scenarios:
-
Global Export & Localization: When you need to remove the original dialogue to dub in a local language (D / ME Separation).
-
Copyright Compliance: When a specific music license expires and only that track needs to be replaced (DE / M Separation).
-
Immersive Remastering: When upmixing legacy content into 5.1 channel, Atmos, or Spatial Audio (D / M / E Individual Separation).
-
Content Creation: For creators needing to avoid copyright strikes on platforms like YouTube or wanting to sample specific sound effects.
-
AI Digital Humans & Restoration: For extracting clean voice data to train AI models of late icons or for Voice Conversion (e.g., de-aging a veteran actor's voice).
2. Why DME Separation is a 'Technical Everest'
DME separation is significantly more difficult than standard vocal/instrument separation for the following reasons:
-
Blurred Boundaries (Dialogue vs. Vocal): The hardest part is distinguishing between 'vocals' in the music and 'dialogue' in the film. Generic AI models often lump them together as 'human voice.' For a professional needing to replace dialogue, having background vocals bleed into the dialogue track makes the output useless.
-
Handling NDV (Non-Dialogue Vocalizations): Are coughs, sighs, or crying sounds part of the 'Dialogue' or 'Effects'? The ability to precisely categorize these based on context is the true measure of a model's intelligence.
-
Overlapping Music & Effects: Is a song playing as a ringtone an 'Effect' or 'Music'? AI must determine this contextually based on the narrative situation.
-
Lack of High-Fidelity Datasets: Training a high-quality DME model requires massive amounts of perfectly isolated D, M, and E data. However, studio-grade individual stems from commercial films are nearly impossible to acquire due to security and copyright restrictions.
3. The Gaudio Lab Solution: GSEP-SHQ Architecture & Philosophy
To conquer the technical "Everest" of DME separation, Gaudio Lab developed the GSEP-SHQ (Super High Quality) architecture. GSEP has already proven its excellence on the global stage, winning the CES 2024 Innovation Award, and is widely recognized for delivering world-class instrument separation quality (try it out at Gaudio Studio). Building on this award-winning foundation, our DME separation is a product of strategic design rooted in a deep understanding of audio.
Why a Hybrid Approach? (Architecture Comparison)
Gaudio Lab recognizes the limitations of standard architectures and employs a hybrid strategy to ensure professional-grade results.

By harvesting the strengths of these models, GSEP-SHQ provides the context-awareness of Transformers with the precision of CNNs. Crucially, we treat Diffusion as an optional post-processing module. This allows Major Studios (like Disney or Netflix) to bypass the risk of "Hallucinations" (AI-generated artifacts) and maintain the absolute integrity of the original recording.
Beyond the Numbers: The "Perceptual Quality" Philosophy
Many companies chase high SDR (Source-to-Distortion Ratio) scores, but at Gaudio Lab, we know that "High SDR does not always equal high-quality sound." Just as a speaker’s spec sheet can’t describe the "warmth" of its sound, DME separation has nuances that numbers cannot capture. We prioritize 'Perceptual Perfection'—preserving the original texture and phase integrity that professionals demand, even if it means ignoring "empty" SDR points. (We will dive deeper into "SDR: The Trap of Numbers" in our next post.)
4. Field-Ready Flexibility: Tailored Options for Professionals
Technology is only as good as its usability. Because the mission for a dubbing engineer differs from that of a remastering artist, we provide specialized modes to meet specific production needs.
Choosing Your Mode: Default vs. D2/ME2
Separating dialogue from background vocals is a high-stakes task. Depending on your goal, you can choose the optimal path:
-
Default Mode (The Standard for Dubbing): This mode strictly isolates Dialogue (D) from Vocals (V) in the music. It is essential for localization and dubbing where the dialogue track must be 100% clean for replacement.
-
D2 / ME2 Mode (The Choice for Remastering): This mode groups Dialogue and Vocals into a single 'Voice' category. By reducing the complexity of the separation, it minimizes artifacts and maximizes sonic richness—ideal for immersive remastering (Spatial Audio) where preserving the original audio’s "vibe" is paramount.
5. Conclusion: Technology That Restores the Value of Audio
Gaudio Lab’s DME Separation is more than just a filter; it is an audio time machine that connects the creator's original intent to future formats. Our quality has been verified by the rigorous standards of global OTT giants and major broadcasters.
From massive studios to individual creators, Gaudio Lab is here to ensure your precious content is delivered to the world with the clearest, most vivid sound possible.
Next Steps
Ready to unlock the full potential of your audio? Take the next step today.
-
Try DME Separation Now: Test the performance with your own video files.
-
See the Results: Explore real-world cases powered by Gaudio Lab’s DME technology.
-
Business Inquiry: Interested in premium solutions or technical integration?


Our audio technologies support various devices and platforms.
