왜 글로벌 OTT는 가우디오랩을 찾을까? AI DME 분리 기술의 끝판왕
왜 글로벌 OTT는 가우디오랩을 찾을까?
AI DME 분리 기술의 끝판왕
소리를 아는 AI 전문가가 만든 프리미엄 오디오 음원 분리의 기준
"단순히 파형을 계산하는 AI와 소리의 문맥을 깊이 있게 이해하는 AI의 결과물은 하늘과 땅 차이입니다."
글로벌 OTT 플랫폼과 프리미엄 콘텐츠 스튜디오들이 가장 까다로운 프로젝트에서 가우디오랩을 파트너로 선택하는 이유는 명확합니다. 우리는 숫자로만 증명되는 성능을 넘어, 실제 들리는 소리의 질감과 무결성을 최우선으로 생각하는 '오디오 전문가'들이 만든 AI이기 때문입니다.
오늘은 마스터 오디오에서 대사(D), 음악(M), 효과음(E)을 완벽하게 되살려 콘텐츠의 가치를 극대화하는 기술, 가우디오랩 DME Separation의 비하인드 스토리와 그 밑바탕이 된 GSEP-SHQ 아키텍처를 소개합니다.
1. DME Separation이란 무엇인가?
오디오의 3요소: D, M, E
영상 콘텐츠의 사운드는 크게 세 가지 성분으로 구성됩니다.
-
Dialogue (대사): 인물의 목소리 및 대화 성분
-
Music (음악): 배경음악(BGM), 삽입곡 및 주제가
-
Effects (효과음): 폴리(Foley), 앰비언스(Ambience), 특수 효과음 등 대사와 음악을 제외한 모든 음향 요소
DME 분리는 이미 하나로 믹싱된(Mixed) 마스터 오디오 파일에서 이 세 가지 요소를 깨끗하게 개별 트랙으로 추출해내는 기술입니다. 일부 업계에서는 대사(D)와 음악/효과음(ME)을 분리하는 작업에서 파생하여 ‘M&E 분리’라고 부르기도 하며, 넓게는 '음원 분리(Source Separation)' 혹은 '스탬 분리(Stem Separation)'의 영역에 속합니다.
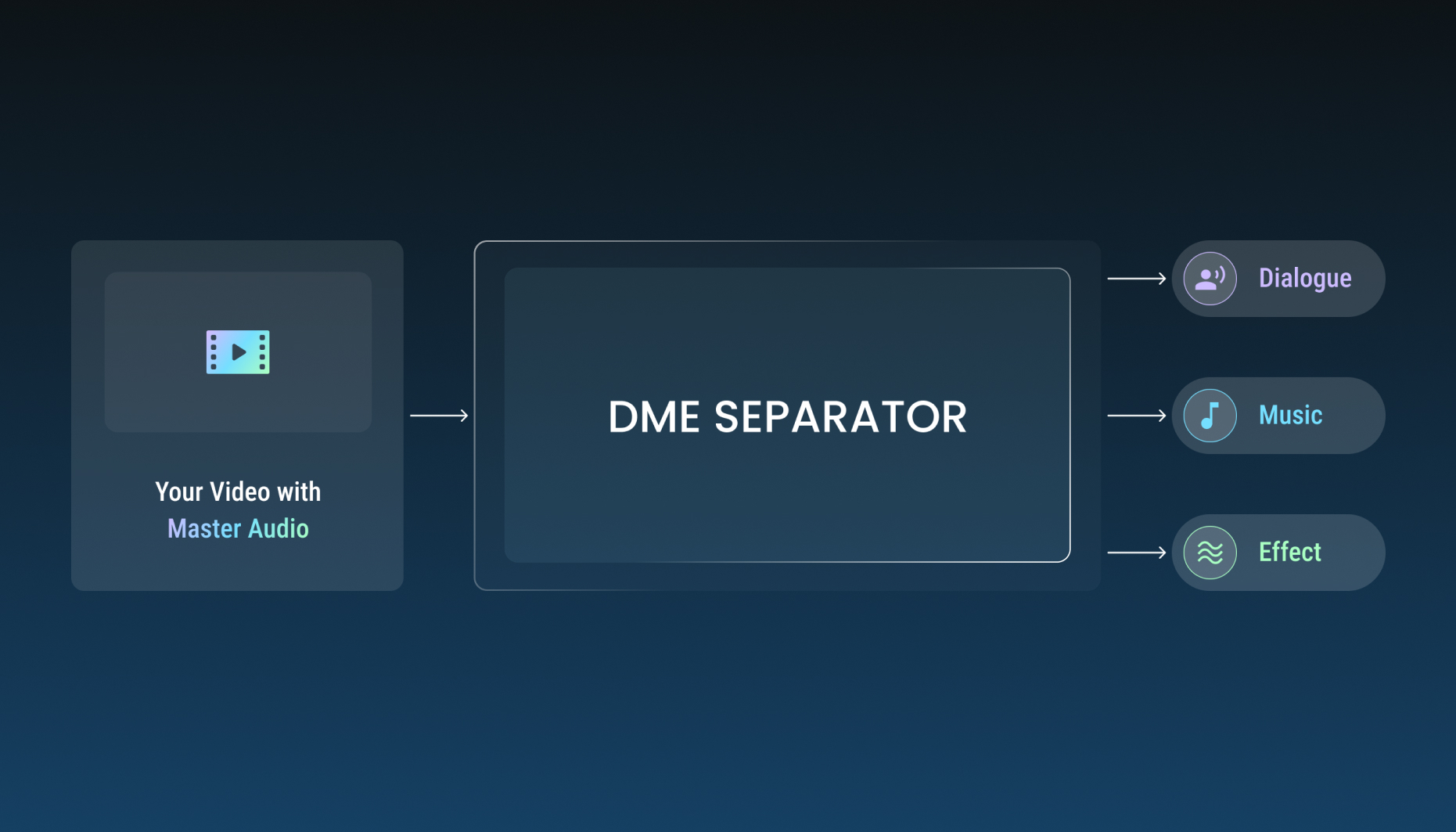
[그림: 가우디오랩의 DME 분리 기술]
누구에게, 왜 필요한가?
제작 현장에서는 촉박한 일정이나 관리 미비로 인해 개별 스탬(Stems) 트랙을 확보하지 못하거나 유실하는 경우가 빈번합니다. 다음과 같은 시나리오에서 오디오 후반 작업을 위해 DME 분리는 필수적입니다.
-
해외 수출 및 로컬라이징: 원본 대사만 제거하고 현지어 성우의 음성을 입혀야 할 때 (D / ME 분리)
-
저작권 리스크 해결: 특정 음악의 라이선스 만료로 인해 해당 곡만 교체해야 할 때 (DE / M 분리)
-
이머시브 리마스터링: 구작 콘텐츠를 5.1 채널이나 공간 음향(Spatial Audio) 등 차세대 포맷으로 재구성할 때 (D / M / E 개별 분리)
-
콘텐츠 크리에이션: 유튜브 등 플랫폼에서의 저작권 침해 방지, 혹은 특정 효과음의 재사용(Sampling)이 필요할 때
-
AI 디지털 휴먼 및 복원: 타계한 배우의 음성을 추출하여 AI 학습 데이터로 활용하거나, 노배우의 목소리를 젊은 시절의 톤으로 변조(Voice Conversion)하기 위한 전처리 작업 시
DME 분리는 과거에는 불가능했던 수많은 사운드 편집 업무를 가능하게 만드는 '오디오 솔루션의 치트키'와 같습니다.
2. DME 분리가 '기술적 난제'인 이유
일반적인 보컬/악기 분리보다 DME 분리는 다음과 같은 이유들로 훨씬 더 높은 난이도를 요구합니다.
-
경계의 모호함 (Dialogue vs Vocal): 음악 속의 '보컬'과 영상 속 '대사'를 변별하는 것이 가장 큰 난관입니다. 범용 모델은 둘 다 목소리로 인식해 합쳐버리지만, 전문가에게 보컬이 섞인 대사 트랙은 무용지물입니다.
-
NDV(Non-Dialogue Vocalizations)의 처리: 기침, 한숨, 울음소리 같은 비언어적 음성을 대사로 볼지 효과음으로 볼지, AI가 문맥적으로 판단해야 합니다.
-
Music vs Effects의 중첩: 극 중 휴대폰 벨소리로 흐르는 노래처럼 상황에 따라 카테고리가 달라지는 소리들을 정교하게 구분해야 합니다.
-
고품질 데이터셋의 부재: 보안과 저작권 문제로 인해 상업 영화 수준의 완벽히 분리된 고품질 스탬 데이터를 확보하는 것 자체가 매우 어렵습니다.
3. 가우디오랩의 해법: SHQ 아키텍처와 분리 옵션
가우디오랩은 이러한 난제를 해결하기 위해 독자적인 GSEP-SHQ(Super High Quality) 아키텍처를 구축했습니다. 이는 단순한 모델의 조합이 아니라, 소리에 대한 깊은 이해를 바탕으로 한 전략적 설계의 결과입니다. GSEP은 이미 CES 2024 혁신상을 수상하며 대외적으로도 그 기술력을 입증받았으며, 악기 분리 품질에 있어서는 이미 글로벌 최고 수준으로 평가받고 있습니다(가우디오 스튜디오에서 체험하세요). 가우디오랩의 DME 분리는 이처럼 세계적으로 인정받은 원천 기술을 바탕으로, 소리에 대한 깊은 이해를 더해 완성한 전략적 설계의 결과입니다.
왜 하이브리드 전략인가? (아키텍처별 비교)
가우디오랩은 기존 아키텍처들의 한계를 극복하기 위해 각 모델의 장점만을 취하는 하이브리드 전략을 취합니다.

가우디오랩은 Transformer의 맥락 파악 능력과 CNN의 정밀함을 결합하여 최고의 분리도를 구현합니다. 특히, 존재하지 않는 소리를 만들어내는 할루시네이션(Hallucination) 리스크를 방지하기 위해 Diffusion 모델을 독립적인 후처리 모듈로 설계하여 원하는 경우 끌 수 있도록 했습니다. 이는 원본 무결성을 중시하는 Disney, Netflix 등 메이저 스튜디오의 엄격한 기준을 충족하기 위한 전략적 선택입니다.
수치를 넘어선 가치: '청감 품질(Perceptual Quality)'에 대한 집착
흔히 성능 지표로 SDR(Source-to-Distortion Ratio)을 사용하지만, 가우디오랩은 "SDR 수치가 높다고 반드시 실제 음질이 좋은 것은 아니다"라는 점에 주목합니다. 수치는 높지만 디지털 노이즈가 끼는 모델보다, 원음의 질감과 위상을 완벽히 보존하는 모델이 현장에서 선택받기 때문입니다. 가우디오랩의 기술은 이 **'청감상의 완벽함'**에 초점이 맞춰져 있습니다. (이에 대한 상세 내용은 다음 편 'SDR의 함정'에서 다룰 예정입니다.)
4. 전문가를 위한 실무적 유연성: 맞춤형 분리 옵션
기술은 실제 현장에서 유용하게 쓰일 때 가치가 있습니다. 가우디오랩은 작업자의 목적(더빙 vs 리마스터링)에 따라 최적의 결과물을 얻을 수 있도록 세심한 옵션을 제공합니다.
작업 목적에 따른 선택: Default vs D2/ME2
대사와 음악 속 보컬을 어떻게 처리할 것인지에 따라 두 가지 모드를 선택할 수 있습니다.
-
Default Mode: 대사(D)와 음악 속 보컬(V)을 엄격하게 분리합니다. 배경음악에 보컬이 있더라도 깨끗한 대사 트랙을 추출해야 하는 더빙 작업에 필수적입니다.
-
D2 / ME2 Mode: 대사와 보컬을 하나의 '목소리' 카테고리로 묶어 분리합니다. 분리 과정에서의 음질 열화를 최소화하여 소리의 풍성함과 원형 보존이 중요한 이머시브 리마스터링 작업에 압도적인 가치를 제공합니다.
5. 결론: 영상 오디오의 가치를 되살리는 기술
가우디오랩의 DME Separation은 단순한 필터링 기술이 아닙니다. 사라질 뻔한 콘텐츠에 새 생명을 불어넣고, 창작자의 의도를 미래의 포맷으로 이어주는 타임머신입니다.
이미 글로벌 OTT와 대형 방송국의 까다로운 품질 검증을 통과한 가우디오랩의 기술력. 이제 여러분의 소중한 콘텐츠가 더 넓은 세상으로, 더 생생한 목소리로 전달될 수 있도록 가우디오랩이 함께하겠습니다.
---
Next Step
당신의 콘텐츠에 새로운 가능성을 더하고 싶으신가요? 지금 바로 확인해 보세요.
-
DME 분리 직접 체험하기: 당신의 영상 파일로 성능을 테스트해 보세요.
-
기술력 확인하기: 가우디오랩의 DME 분리 기술이 적용된 실제 사례를 만나보세요.
-
비즈니스 협업: 프리미엄 솔루션 도입 및 기술 문의가 필요하시다면?


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
