ICML 논문 맛보기: A demand-driven perspective on Generative Audio AI
ICML 논문 맛보기: A demand-driven perspective on Generative Audio AI
(Writer: Rio Oh)
안녕하세요. 저는 가우디오랩 AI 리서치 팀에서 사운드 생성 모델인 FALL-E 연구를 하고 있는 리오(Rio)입니다🙂 저는 생성 모델에 관심이 많은데요, 최근에는 생성 모델의 접근 방식을 다른 태스크에 적용해 보기 위한 연구를 하고 있습니다.
저희 팀에서는 요 근래에 DCASE를 준비하는 한편, 실제 산업에 적용되기 위해선 어떤 점을 개선해야 할까 고민해왔었습니다. 그 내용을 담아 이번 ICML 워크샵에서 발표할 예정인데요, 여러분께 그 내용을 미리 소개해 드리려 합니다!
들어가며
최근 DCASE Challenge에서 일궈낸 가우디오랩의 성과에 대해 블로그로 소개해 드린 것 기억하시나요? 그동안 가우디오랩에는 또 하나의 좋은 소식이 있었습니다. 바로 ICML 워크샵에 저희가 제출한 논문이 억셉된 것입니다. (룰루🥰)
ICML은 NeurIPS와 함께 세계 최고의 인공지능 학회로 뜨거운 주목을 받고 있습니다. 올해의 학회 기간 중 마지막 이틀 동안 주제 별로 워크샵이 진행되는데요. 최근 핫한 세부 주제를 선정해 워크샵을 진행하고, 더블 블라인드 피어 리뷰를 통과한 논문만 이 자리에 설 수 있답니다.
사운드 생성 AI, 가우디오랩이 먼저 걸어와보니
사실 텍스트, 이미지 분야와 비교하면 (음성을 제외한) 오디오 생성은 아직 이 산업의 걸음마 단계를 걷고 있다고 할 수 있습니다. 우리에게 익숙한 텍스트 분야를 넘어 이미지 분야를 보자면, DALL-E 등의 Diffusion 모델 등을 활용한 상용 및 비상용 서비스들이 나와 있고, 대중들도 쉽게 사용할 수 있도록 되어 있죠. 그러나 오디오는 기술의 성숙도, 컴퓨팅 자원의 한계 등으로 아직 공개된 서비스가 없는 상황입니다. (논문의 실험 결과 공유를 위한 데모나 모델 공유는 조금씩 이루어지고 있지만, 일반인들이 사용할 수 있는 단계의 서비스는 거의 없다고 보아도 무방한 상황이죠.)
이런 환경 하에서, 가우디오랩은 단순한 데모를 넘어 기존 사업의 패러다임을 완전히 뒤집을 만한 AI 제품을 만들 수 있기를 꿈꾸며, 현재 당면한 상황과 한계를 정리하는 과정을 거쳤습니다. 연구단계의 오디오 AI 제품들이 세상의 빛을 볼 수 있도록 업계의 소리를 직접 듣고자 하는 귀중한 시도를 했는데요. 가우디오랩은 이를 통해 (물론 연구 자체도 매우 중요합니다만 그에 함몰되지 않고) 산업 전반의 실상과 업무 프로세스를 조명하고 앞으로의 연구방향을 더 날카롭고 정확하게 수립하고자 합니다.
그리고 이를 2023의 Challenges in Deployable Generative AI라는 워크샵에서 발표합니다!
(일시: Fri 28 Jul, 9 a.m. HST & Sat 29 Jul, 4 a.m. KST)

[사진 = 워크샵 포스터]
잠깐, 상단 Motivations에 언급된 가우디오랩의 FALL-E (폴리)가 뭐냐고요?
가우디오랩의 FALL-E는 텍스트나 이미지 입력에 대응되는 소리를 생성해 내는 AI 기반 Text-to-Sound Generation 기술입니다. 실제 존재하는 소리(고양이 울음소리, 천둥소리 등) 뿐만 아니라 무한한 가상 세계의 소리(호랑이 담배 피우는 소리 등)을 만들어냅니다. 소리를 재료로 콘텐츠 영역을 무한히 확장할 수 있죠. 덕분에 생성된 소리들은 콘텐츠 및 가상환경 구현 과정에서 효과음 및 배경음으로 활용될 수 있고, 몰입감 있는 경험을 제공하는 모든 환경에 필수적인 소리 기술로 자리매김하리라 기대를 한몸에 받고 있습니다.
폴리를 조금 더 알려드릴게요!
이름에서 눈치채셨나요? Foley sound의 의미를 담고 있기도 합니다.
Foley는 영화 등의 소리 후반작업에서 음향효과를 재현하는 것을 의미합니다. 밥그릇 두 개를 번갈아 땅에 부딪히며 말발굽 소리를 만들어 내는 것처럼요. 1930년대에 유래된 말로, Jack Foley의 이름을 따서 지어졌죠.
Foley는 콘텐츠 제작에 반드시 필요한 과정인데요. 녹음된 음원을 재사용하기도 어렵고, 경제성도 떨어져 지금까지도 수작업에 의존하고 있는 실정입니다.
그래서 Generative 모델로 해결하면 좋은 문제이고, 가우디오랩은 이 기술에 집중하고 있어요.

이번 연구를 통해 확인한 어려움들은 어떤 것들이 있었냐면요.
가우디오랩은 이번 논문을 준비하며 실제 영화 음향 업계에 종사하시는 분들을 대상으로 설문 조사를 진행하여 논문에 포함하기도 했습니다. 살짝 결과를 공유드리자면, 저희가 발견한 가장 큰 한계점은 1) 음질이 더욱 좋아야 한다는 것과 2) 작은 디테일까지도 컨트롤할 수 있어야 한다는 것이 있었죠. [논문 전체 보러 가기]
그래서 가우디오랩은 FALL-E를 만들며 이 문제를 어떻게 풀어냈을까요?
깨끗한 고품질 데이터가 적다는 점이 어려운 점 중 한 가지였습니다. 게다가 생성 모델에서는 아주 많은 데이터가 필요하기 때문에 문제였죠. 가우디오랩이 생각한 해결책은 깨끗한 데이터와 상대적으로 덜 깨끗한 데이터를 동시에 같이 사용하되 모델에게 condition을 주는 방법이었습니다.
생성 모델은 생성할 샘플뿐만 아니라 모델을 생성하는 데 도움이 되는 다양한 힌트(텍스트, 카테고리, 비디오 등)를 함께 학습 데이터로 활용하는데, 이 데이터가 어떤 데이터 셋에서 가져왔는지를 라벨 형태로 추가 힌트를 주는 것이죠.
이렇게 되면 모델이 소리를 생성할 때, 깨끗한 소리를 생성할지, noisy 한 소리를 생성할지 정할 수 있게 되고, 실제로 저희가 DCASE Challenge에 참여했을 때, 다양한 소리를 생성하면서 음질도 좋다는 평을 받기도 했습니다. 당시 객관 평가 지표 (FAD)로 top contender를 각 트랙 별로 4팀씩 선발한 뒤 청취 평가를 진행했는데요. 보시다시피 가우디오랩은 깨끗한 음질과 수없이 다양한 소리를 생성해낼 수 있는 다양성 분야에서 높은 점수를 기록했습니다. 모든 소리를 생성할 수 있는 모델인 FALL-E로 일부 카테고리에 한정해 심사하는 대회에 나가 몸풀기 한 것치고 꽤 좋은 성과를 냈다고 할 수 있어요.
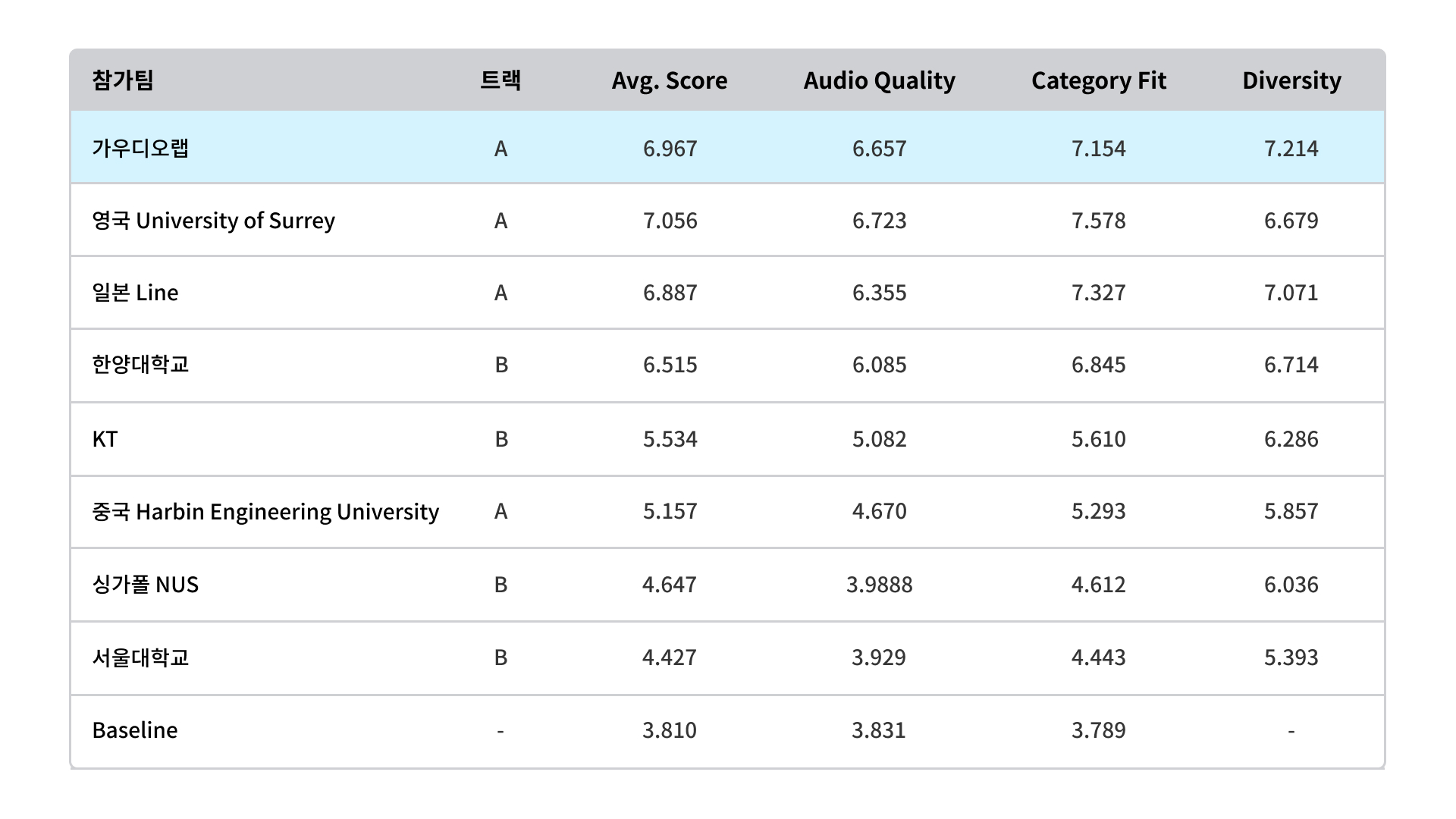
DCASE 2023 Challenge Task 7 결과 > 여기서 더 자세히 보실 수 있어요.
FALL-E는 지금까지 공개된 모델 중 가장 음질이 좋은 모델이라 평가할 수도 있지만, 저희는 여기서 멈추지 않고 더 좋은 소리를 만드는 모델을 위해 고민하는 중이기도 합니다.
사실, FALL-E가 세상에 나오기까지 이런 진통이 있었어요!
가우디오랩이 처음 FALL-E에 대한 아이디어를 얻고 연구를 시작한 2021년 당시에는 텍스트 기반의 AI 폴리 합성 모델에 관련된 논문은 거의 없는 수준이었습니다. 게다가 영상 기반의 효과음 연구도 매우 제한된 카테고리이거나 모델 성능이 promising 해 보이진 않았죠. (물론 지금은 관련 논문도 많이 나온 상황이지만요!)
연구 측면에서 방향성을 고민하기도 했으나, AI 디렉터인 근우가 팀의 에너지를 한곳으로 이끌어주며 그동안 explore 하며 쌓인 지식과 경험들을 exploit 하면서 힘을 모아 달려갈 수 있었던 것 같습니다. 당시에는 의구심이 들기도 하고 여러 고민이 들기도 했지만, 지금 돌아보니 이렇게 계속해서 방향을 정리하고 조정하는 과정이 ‘맞는 방향'을 찾는 좋은 과정이지 않았을까? 하는 생각이 듭니다.
“저쪽이다” 하면서 같이 우당탕탕 하면서 달려갔다가, 잠깐씩 숨 고르면서 방향을 fine-tuning 하면서 달리는 것, 당면한 상황에 맞춰 유연하게 방향을 수정해 결국은 목표한 곳에 당도하는 것, 그것이 가우디오랩 AI 리서치 팀이 일하는 방식이 아닐까 싶습니다.
정신 차려보니 DCASE를 주관하고, 가볍게 참가했는데도 아주 좋은 성적을 냈고, 저는 결국 하와이에 와있습니다. 사실 하와이는 논문이 통과되지 않는 경우가 생기더라도 더 많은 시야를 보기 위해 오는 것으로 결정되었었는데, ICML 논문이 억셉되며 더욱 의미 있는 출장이 되었으니 아주 신나고 알차게 보내다 한국에 들어갈 생각입니다.
그럼 하와이에서 올리는 글을 마칩니다! 🏝

다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
