Vision Pro 등장: 다중 음원이 존재하는 환경에서의 RIR 예측
Vision Pro의 등장: 다중 음원이 존재하는 환경에서의 RIR 예측은 어떻게 하면 될까요?
들어가며
안녕하세요, 가우디오랩에서 오디오와 AI 연구 개발을 하고 있는 모니카입니다.
최근에 Apple에서 Vision pro가 소개되면서 Spatial technology가 다시 한번 뜨거운 관심을 받게 되었습니다. 오디오와 관련된 기술도 언급되었는데요, 사용자가 위치한 공간에 대한 정보를 학습해 더욱 더 실감있는 오디오 경험을 제공한다고 합니다. 마-침 가우디오랩에서도 작년에 이와 같은 맥락에서 연구를 진행했기 때문에, 설레는 마음으로 이번 글에서 소개해보려고 합니다.

둠칫 둠칫 두둠칫
Room Impulse Response, 한 가지만 기억하세요.
“어떤 소리를 특정 공간에서 나는 것처럼 만들고 싶다!”라면 Room Impulse Response (RIR)만 알면 됩니다.
RIR은 Impulse signal(아래 Figure 1에서 한 남성의 총소리)이 해당 공간 안에서 어떻게 울려 퍼지는 지를 측정한 신호입니다. 어떤 소리든 특정 공간의 RIR 과 convolution하게 되면 그 공간에서 나는 소리처럼 들리게 만들 수 있습니다. 따라서 RIR은 [그 공간에 대한 정보를 담고 있는 매우 유용한 데이터]라고 설명드릴 수 있습니다.
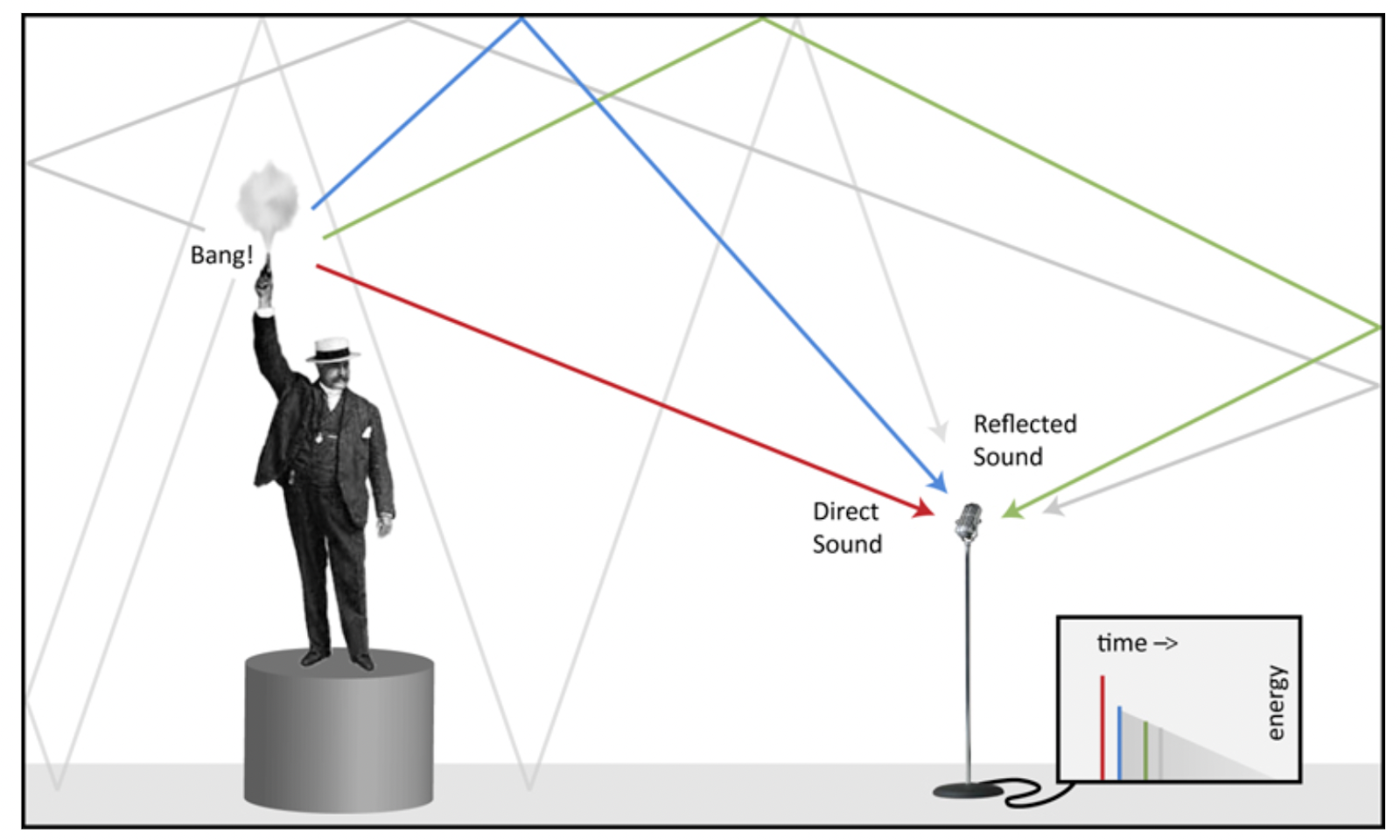
Figure 1 - 출처: https://www.prosoundweb.com/what-is-an-impulse-response/
그렇다면 RIR은 어떻게 구할 수 있을까요?
원하는 공간의 RIR을 구하고 싶다면 마이크를 들고 가서 직접 측정하는 것이 가장 정확한 방법입니다. 하지만 측정하는 것은 매우 번거로운 일입니다. 장비도 필요하고 시간도 많이 소모됩니다. 물리적인 제약으로 그 공간에 직접 갈 수 없을 수도 있고요. 다행히도 머신러닝 기술의 개발로 직접 가지 않아도 예측할 수 있는 방법들이 연구되고 있습니다. 예를 들면, 특정 공간에서 녹음된 소리(ex. 사람 목소리)만으로부터 그 공간의 RIR을 예측하는 연구가 그 중 하나입니다.
TWS 사용자들의 주변 소리를 녹음해서 실시간으로 RIR을 예측할 수 있을까?
증강 현실에서 사용자가 더 실감있는 경험을 하려면 가상 음원들이 사용자와 같은 공간에 있는 것처럼 들려야합니다. 그렇다면 사용자의 공간에 대한 정보를 얻어야 하는데요, 저희는 TWS를 이용해 주변 소리를 녹음해서 머신러닝으로 분석하는 방법을 연구해보기로 했습니다.
사용자가 있는 공간에서 실시간으로 예측해야하는 상황에서는 분명 한 명 이상의 사람과 사물이 소리를 내고 있을 것입니다 (= 다중 음원 / multiple sources). 하지만 과거 연구에서는 주로 한명의 사람이 발화하는 오디오 신호 (이하 단일 음원 / single source) 로부터 RIR을 예측하는 방법을 다뤄왔습니다.
단일 음원과 다중 음원인 상황에서의 RIR 예측을 같은 문제라고 생각할 수 있지만, 사실 문제 정의부터 새로 해야할 정도로 다른 주제라고 봐야합니다. 왜냐하면 RIR은 같은 공간이더라도 각 음원들이 어느 공간에서 어느 방향을 보고 있는 지에 따라 다르게 측정되기 때문입니다. 물론 같은 공간이니 공통점도 존재하지만 세부적으로는 다르답니다.
정면에 있는 RIR만 예측하자!
그렇다면 여러 음원들이 녹음된 실제 상황에서는 어떻게 RIR을 예측해야할까요?
여러 방법이 있을 수 있겠지만 가우디오랩은 미래의 우리 제품에 녹아들 수 있는 시나리오에 맞게 정의하기로 했습니다. TWS 사용자를 위해 오디오를 랜더링해야하는 경우를 상상해보니, 정면에 있는 음원에 의해 생성되는 RIR만 예측하는 것이 우선적으로 필요할 것이라는 판단을 내렸습니다. 따라서, Figure 2와 같이 여러 소리들이(아래 그림 내 진한 회색 원형) 녹음되어도 사용자의 정면 1.5미터 거리에 있는 음원에 (파란색 원형) 의한 에서의 RIR을 예측하는 것을 문제로 정의했습니다.

Figure 2 사용자를 중심으로 여러 음원들이 여러 위치에서 소리를 내고 있습니다 (회색 원형).
이렇게 여러 음원들이 존재하는 경우에도 항상 정면 1.5미터 거리에 가상 음원이(파란색 원형) 있다고 가정하고 이곳에서의 RIR을 예측하는 모델을 개발했습니다.
AI 모델 구조는 비교적 최근에 발표된 논문의 모델을 참고해서 만들었습니다. 특정 공간에서 나는 소리를 모델의 입력으로 넣으면 그 공간의 RIR 을 출력하는 것이 기본적인 모델의 작동 방식입니다. 앞서 말씀드렸듯이 대다수의 기존 연구들은 단일 음원만 포함된 데이터셋을 모델 입력으로 이용했습니다 (Figure 3 Top).
하지만 저희는 아래 Figure 3에서 보이는 것처럼, 다중 음원들이 포함된 데이터셋을 모델의 입력으로 사용하는 방법을 제안합니다. Room A에서 측정된 몇개의 RIR들과 anechoic speech signal을 각각 convolution해서 합치는 방법으로 데이터셋을 구축했습니다. 모델의 출력은 사용자 입장에서 정면에 있는 음원의 monaural RIR 하나입니다. 정답이 되는 RIR과 똑같은 RIR을 생성해내도록 손실 함수를 만들어 학습했습니다.

Figure 3 기존 연구에서는 단일 음원인 환경을 모방한 데이터로만 학습을 했지만 (top figure),
저희는 다중 음원인 환경에서의 데이터로 학습하는 방법을 제시했습니다 (bottom figure)
모든 AI 시스템 개발 과정의 꽃인 데이터셋 확보에 저희도 많은 시간을 썼습니다. RIR 데이터는 제법 많지만 한 공간에서 여러 RIR 을 측정한 데이터는 많지 않기 때문인데요. 수 만개의 방을 직접 측정해서 데이터셋을 만드는 것은 불가능에 가깝기 때문에 여러 오픈소스 코드를 활용해 Synthetic 데이터셋을 대량 생산해서 사용했습니다.
결과는?
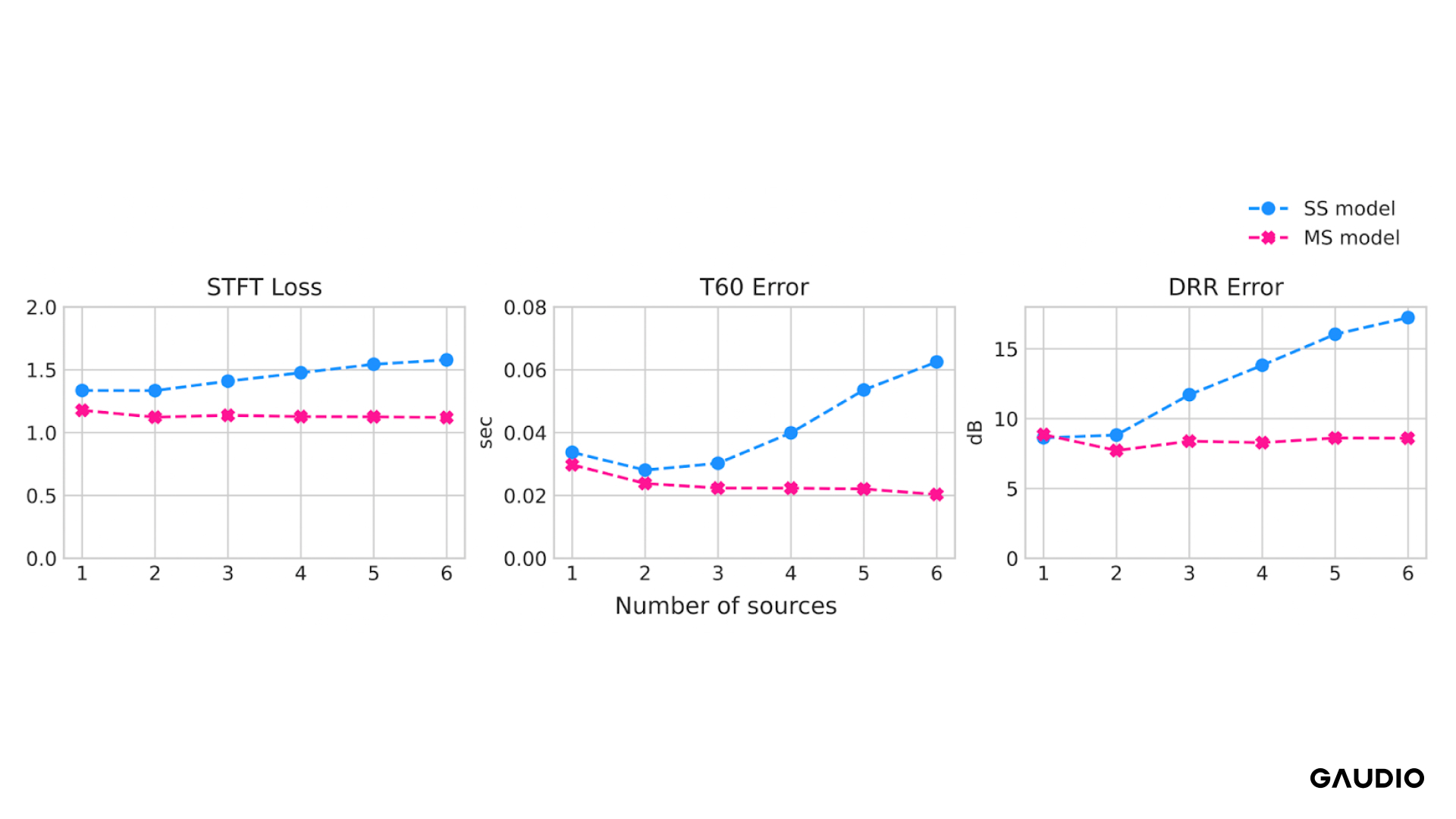
Figure 4 기존에 연구된 방식인 단일 음원 모델 (SS model)과 저희가 제안한 다중 음원 모델 (MS model)이 음원의 갯수가 증가함에 따라 성능이 어떻게 변화하는지 나타내는 표입니다.
Loss 와 Error 값이 증가한다는 뜻은 성능이 저하된다는 것을 의미합니다.
기존에 단일 음원으로만 학습한 모델 (SS model - 파란색)과 저희가 정의한 다중 음원을 이용한 학습 방법대로 (MS model - 분홍색)을 비교해보았습니다. 음원의 갯수를 1개에서부터 6개까지 늘리면서 RIR을 예측한 결과를 위 figure 4에서 보실 수 있습니다. 단일 음원 모델은 갯수가 증가하면 성능이 악화되는 것을 볼 수 있습니다. 하지만 다중 음원 모델은 갯수가 증가하더라도 일정하고 안정적인 성능으로 RIR을 예측하는 것을 확인할 수 있었습니다!
실제 환경에서는 사용자 주변의 음원의 갯수를 미리 알 수 없습니다. 따라서 저희가 제안한 방법처럼 음원의 갯수에 무관하게 모델이 현재 공간의 RIR을 예측할 수 있다면 훨씬 더 몰입감 있는 경험을 제공할 수 있을 것입니다.
이 연구가 더 궁금하시다면!
연구 결과를 바탕으로 저는 실제 가우디오랩의 오피스 공간 3곳에서 직접 녹음한 소리로부터 실시간으로 RIR을 예측하는 시스템을 개발해서 데모를 진행해보기도 했습니다. 각각 다른 특성을 가진 공간이었는데, 모델이 그 공간을 반영하는 RIR을 안정적으로 예측하는 것을 확인할 수 있었습니다! 가우딘들과 청취평가를 진행한 결과 대부분의 사람들이 “정말 이 공간에서 나는 소리 같다!”라는 반응을 보이기도 했지요.
이 연구는 2023년 8월(지금!), AES International Conference on Spatial and Immersive Audio 컨퍼런스에 억셉되어 발표될 예정이기도 합니다.
궁금하신 분들은 이 링크를 통해 확인하세요!


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
