Gaudio Lab's audio generative AI that impressed Nadella
Opening
FALL-E by Gaudio Lab is an Audio generative AI that automatically creates sound tailored to various inputs such as images, text, and even videos.
Sound can be broadly categorized into 1) speech, 2) music, and 3) sound effects. FALL-E is specifically designed to focus on creating 3) sound effects.
While it's relatively easy to find AI that can generate or manipulate voices and music, finding AI capable of generating other types of sounds (like sound effects) is quite challenging.
From the sound of keyboard typing to footsteps, and the rustle of leaves in the wind... There are so many sounds around us! And now FALL-E aims to take on the task of generating these diverse sounds.
Recently, Gaudio Lab has launched a closed demo webpage where users can directly experience FALL-E. Anyone can easily generate the desired sound by simply entering prompts, just like the screen below:
Text to Audio Generation Screen
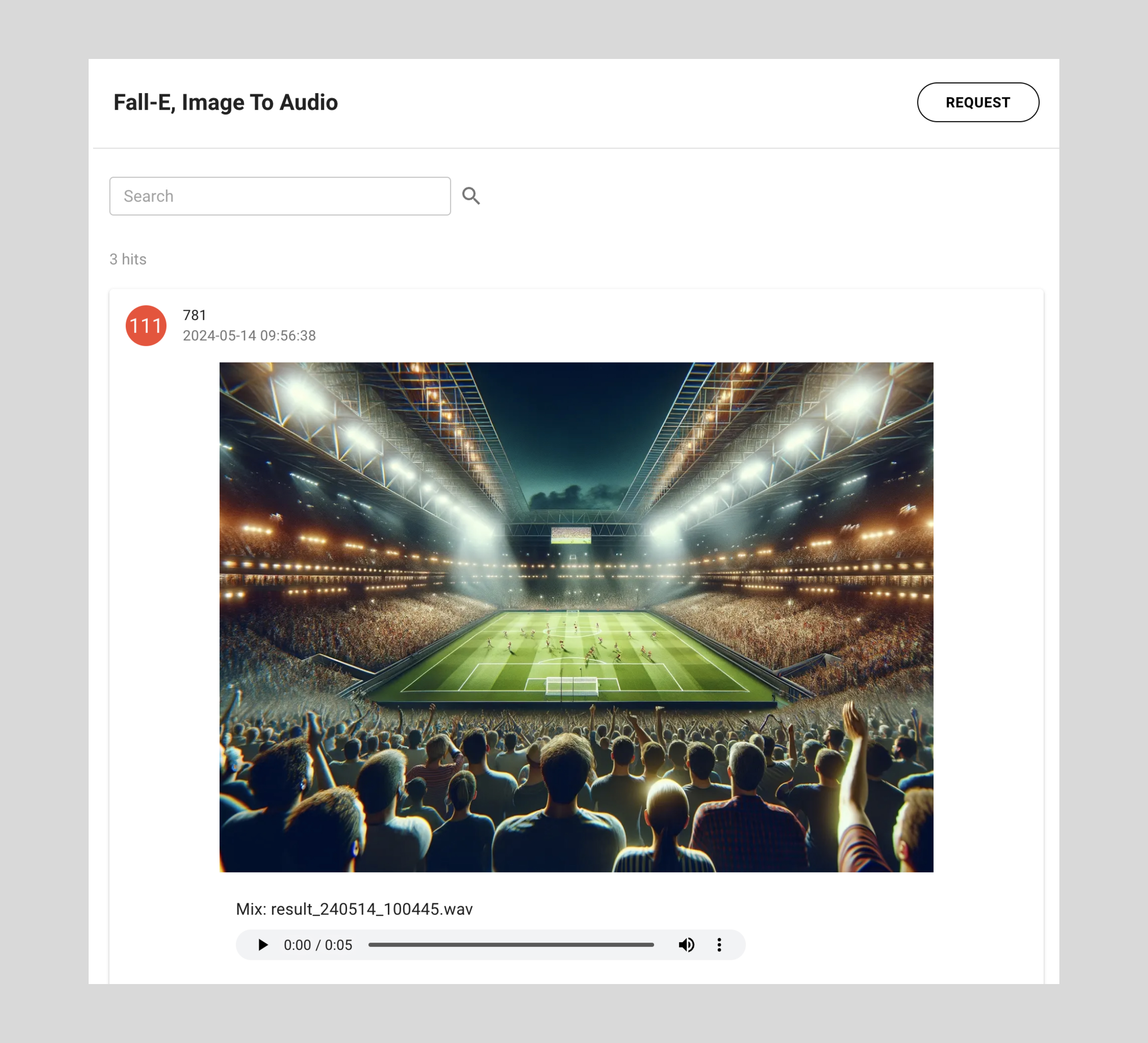
Image to Audio Generation Screen
I'd like to share the experience of AI Times reporter Jang, Semin, who experienced this demo page.
Through this experience, I encourage you to imagine the future that Gaudio Lab will bring.
Now, let's take a look at the full article below!
-
[Firsthand Experience] AI-Generated Sound Effects that Impressed Nadella: How Far Have Gaudio Lab Evolved?
Gaudio Lab (CEO Hyun-oh Oh), a specialist in sound AI, recently announced the release of a closed demo site that allows users to experience their own AI-generated sound effects.
Gaudio Lab's signature generative sound AI, 'FALL-E,' first garnered global attention at CES in Las Vegas this January. This is the same product that stunned Microsoft CEO Satya Nadella, who visited the booth and exclaimed, "Is this really a sound created by AI? Amazing!"
FALL-E is a 'multimodal AI' capable of processing not only text but also images, boasting technology that surpasses that of international competitors. Recently, Gaudio Lab completed its front-end development and is currently testing the solution with a limited number of users through the closed demo.
AI Times participated in the test, accessing the closed demo site to generate sounds based on several criteria.
To begin testing FALL-E’s basic functionality, I started by inputting text. Currently, only English prompts are supported.
The first prompt was "An old pickup truck accelerating on a dirt road." The generated sound accurately depicted the sensation of wheels rolling. Adding a bit more roughness could enhance the effect.
The second prompt was "Ambience of the interior of a crowded, rattling urban train." This one was incredibly realistic, almost indistinguishable from an actual recording.
Next, I tried "A demonic alien creature roaring and screaming," which was chilling enough to send shivers down my spine as soon as the sound played. This technology could be incredibly useful for genres like mystery, thriller, and horror.
Other prompts included "a door closed violently," "stepping on mud after raining," "ghost sound," and "HAHAHA- sound of a murderer chasing someone." All of these produced results that exceeded my expectations.
However, one downside is that it cannot generate dialogue or vocal sounds. For instance, a prompt like "Who is that?" voice with fear did not produce any output.
A Gaudio Lab representative explained, "FALL-E was not developed to handle voices or music; it focuses on sound effects. While it includes non-verbal sounds like sneezing or coughing, generating verbal sounds requires different technologies, such as TTS (text-to-speech)."
Still, what's impressive is that the generated sound effects are of such high quality that they allow you to imagine “an entire story.”
One of the standout features is its ease of use. Similar to image generation AI, it can produce plausible sounds with just a few everyday words, without needing highly detailed or specific descriptions.
So, can even the “subtlest differences” be expressed through sound?
To verify this, I tested various prompts by slightly differentiating factors such as age, emotion, texture of objects, distance of sound, and scale. First, I tested how age differences are expressed through ”the sound of a child's cry.”
I started with the prompt "A child is crying after ruining the test." However, the result wasn't what I expected. The voice sounded too young for a school test scenario. So, I added a specific age setting.
When I input "A 13-year-old boy student is crying after ruining the test," it generated a much more mature voice than before. It was possible to adjust the age using text alone.
To test the texture of objects, I compared chocolate and honey using the common descriptor 'sticky.' While it seemed easy to create distinct sounds for steel and honey, it appeared challenging to express similar viscosities with different sounds.
However, I was astonished upon hearing the results. FALL-E accurately captured the differences between the materials.
For emotion, I used the sound of a dog barking. One prompt was for an angry, alert bark, and the other for a puppy whining to go for a walk. Once again, the differences were clear, and the emotion was effectively conveyed.
Lastly, to gauge distance and scale, I used the sound of “a zombie growl.” I differentiated between “a single zombie growling nearby,” “multiple zombies growling from a distance,” and “multiple zombies growling nearby.”
When the scale was set to one, the sound expression was much more detailed. What was interesting was the difference in distance. Even with the same group of zombies, the sound was faint when they were far away, “as if a wall was blocking them.”
The final test, and the one I was most curious about, was “image input.” This feature is Gaudio Lab's key differentiator and a starting point for their ultimate goal. If entire videos could be inputted to generate sound, it could revolutionize the time needed for film production.
However, this is also technically challenging. While text input clearly conveys the user's intent, images require the AI to analyze many more aspects. The AI must reanalyze and calculate elements like emotion, distance, scale, texture, and age that were tested previously.
The most fascinating result was that the AI did not produce just one sound. FALL-E provided up to three separate sounds reflecting different objects and situations within the image, and a final “integrated version,” offering a total of four sounds. For example, in a scene of two people fighting, it generated sounds like ▲ clothes rustling, ▲ impact with the floor, and ▲ a window breaking.
For image inputs, I used both “generated images” and “official movie stills.”
When I input a cartoon-style image generated by Lasco.ai, FALL-E did not recognize all objects accurately. In a scene where a girl and a dog were playing, it generated the sound of the dog barking but not the girl's laughter. This likely stems from the inherent ambiguity in drawings.
So this time, I used live-action images. I chose intense movie scenes from “John Wick,” “Transformers,” “Terminator,” and “Fast & Furious.”
While the AI recognized all the objects in these images, the sounds it generated were not as intense as the actual movie sound effects. It seems challenging to convey the full intensity of a movie from just a single still. If the AI could understand the context of the film, it might produce stronger sound effects.
I also tested images where the sounds were not obvious, such as a person riding a unicorn or a cow working. Even in these cases, the AI generated plausible sounds.
As seen in the video, the overall results of this test exceeded expectations. If CEO Nadella were to see this version, he would undoubtedly be even more astonished.
Gaudio Lab stated that they are striving to make it easy for anyone to create the desired sound. A representative mentioned, "This test is significant because it allows non-experts to experience AI sound generation, aligning with our company vision."
Given their history of developing high-quality, advanced technology, if their multimodal capabilities expand to include video, I believe the prediction that "Gaudio Lab's technology will be in every movie and video" could very well become a reality.
Reporter Jang Se-min semim99@aitimes.com
Original Article : AI Times (AI Times )


Our audio technologies support various devices and platforms.
