ICML Paper Preview: A demand-driven perspective on Generative Audio AI
ICML Paper Preview: A demand-driven perspective on Generative Audio AI
(Writer: Rio Oh)
Greetings. I am Rio, a researcher at Gaudio Lab’s AI Research Team, dedicated to the development of the sound generation model, FALL-E. I have a keen interest in generative models, and my recent work involves the exploration of how generative model strategies can be applied to diverse tasks.
Our team has been reflecting on the essential areas that require enhancements for real-world, industrial applications. We aim to present these insights at the upcoming ICML workshop, and I’m pleased to provide a sneak preview of our findings!
Introduction
Through our blog, we’ve previously highlighted Gaudio Lab’s achievements in the DCASE Challenge.
We’re thrilled to share another significant milestone from Gaudio Lab: the acceptance of our paper for presentation at the ICML workshop (Hooray🥰).
ICML, in conjunction with NeurIPS, is recognized as one of the world’s leading AI conferences, attracting considerable global attention. Over the final two days of the conference period, thematic workshops are organized. Only papers that have passed a stringent double-blind peer review process are selected for presentation at these sessions.
Generative Audio AI: Pioneering the Field with Gaudio Lab
Comparatively, audio generation (excluding speech) is still in its infancy when contrasted with the text and image sectors. Looking beyond the familiar domain of text into images, a range of commercial and non-commercial services are already utilizing Diffusion models such as DALL-E and are easily accessible to the public.
However, audio lags behind with no public services yet launched, primarily due to technological maturity and computational resource constraints. (While sharing of demos and models for disseminating experimental results from papers is gradually increasing, the availability of services that the general public can utilize is virtually non-existent.)
In this challenging environment, Gaudio Lab aspires to create AI products that transcend mere demos, potentially revolutionizing existing paradigms. We’ve embarked on a process to evaluate and address the prevailing challenges and limitations. This important endeavor, aimed at tuning into the industry’s voice, seeks to bring research-stage audio AI products into mainstream visibility.
Through this, Gaudio Lab intends to stay connected with the broader industry context and its processes (while maintaining a strong focus on research), striving to refine our future research directions with greater precision.
We are excited to present our insights and learnings at the 2023 Challenges in Deployable Generative AI workshop! (Scheduled for: Fri 28 Jul, 9 a.m. HST & Sat 29 Jul, 4 a.m. KST)

[image = workshop poster]
Hold on, what exactly is Gaudio Lab’s FALL-E mentioned in the "Motivations" section?
FALL-E is an innovative technology from Gaudio Lab, utilizing AI-based Text-to-Sound Generation to create sounds in response to text or image inputs. It can generate not only actual real-world sounds, such as a cat’s cry or thunder, but also limitless virtual sounds, for instance, the sound of a tiger smoking – an imaginative representation of an unreal scenario.
This ability significantly broadens the horizons for content creation through sound. The produced sounds can serve as sound effects and background noises during the development of content and virtual environments. Accordingly, FALL-E is projected to be an essential sound technology in all environments offering immersive experiences.
Allow me to explain more about FALL-E!
Did the name give you a hint? It’s also an allusion to Foley sound.
Foley is a technique used in film post-production to recreate sound effects. For instance, creating the sound of horse hooves by alternately hitting two bowls on the ground. The term originated in the 1930s, named after Jack Foley.
Foley sound creation is vital in content production. However, reusing recorded sounds and associated economic inefficiencies remain challenges, resulting in a continued reliance on manual work.
As a result, addressing this issue with a generative model presents a promising approach – an approach Gaudio Lab is focused on.

So, what were the challenges we encountered during this research?
In preparing this paper, Gaudio Lab conducted a survey involving professionals from the film sound industry, and the responses were incorporated into our research. To provide a brief overview of our findings, the most significant hurdles were: 1) the need for superior sound quality, and 2) the ability to exercise detailed control. [Link to the full paper]
How exactly did Gaudio Lab overcome these challenges during FALL-E’s development?
One significant hurdle was the scarcity of clean, high-quality data. This issue was compounded by the large quantity of data needed by generative models. Gaudio Lab’s solution was to use both clean and relatively noisier data in tandem, incorporating specific conditions into the model.
Generative models draw from more than just the samples they aim to create; they also use a variety of supplementary information, such as text, categories, and videos, as learning inputs. We added another layer of context to this process by tagging each dataset based on its source.
This method enabled the model to decide whether to generate clean or noisy sounds during the production process. Indeed, during our participation in the DCASE Challenge, our model earned praise for its ability to produce a wide array of sounds while maintaining high audio quality.
The competition involved selecting the top four contenders per track using an objective evaluation metric (FAD), which was followed by a listening evaluation. As evidenced by the results, Gaudio Lab scored highly in categories assessing both clean sound quality and the ability to generate a diverse range of sounds.
These impressive results were achieved even though we only participated in certain categories of the competition with our FALL-E model, which is capable of generating all types of sounds.
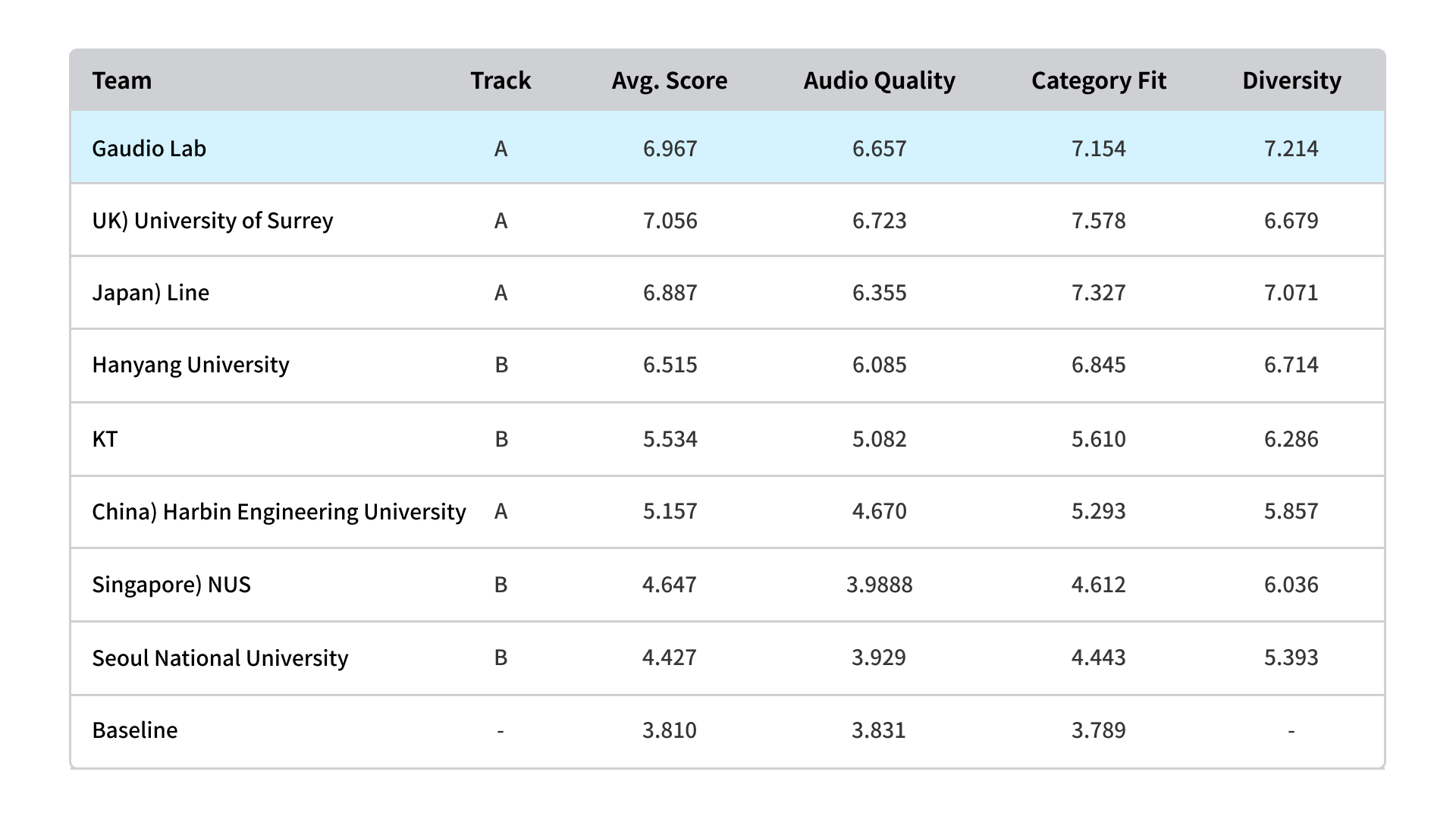
[image = DCASE 2023 Challenge Task 7 Results] :: You can see more details here.
Although FALL-E could be considered the best-performing model in terms of sound quality among those currently available, we do not intend to stop here. Gaudio Lab is continuously exploring ways to develop models that can generate even more superior sounds.
In truth, the birth of FALL-E was not without its trials and tribulations.
When Gaudio Lab first conceived the idea of FALL-E and initiated the research in 2021, there were scarcely any scholarly papers addressing text-based AI Foley synthesis models. Furthermore, research into video-based sound effects was somewhat limited, and the performance of such models didn’t seem particularly promising. (It is worth mentioning that the landscape has significantly changed since then with a plethora of relevant research now available.)
At times, we found ourselves pondering the direction of our research. Yet, it was Keunwoo’s (Link) effective leadership that helped harness the team’s collective energy. He leveraged the accumulated knowledge and experiences we had gathered over time, leading us to press forward despite initial doubts and concerns. Looking back, I can’t help but think that this continuous process of defining and adjusting our direction was a crucial step in discovering the ‘right path.’
As a team, we enthusiastically threw ourselves into the project, pausing occasionally to fine-tune our trajectory. We remained flexible, adjusting our course in response to new challenges, and ultimately reaching our intended goal. This, I believe, is an apt representation of Gaudio Lab’s AI Research team’s approach to work.
Before we knew it, we were not only organizing the DCASE but also participating in it. We were thrilled to achieve excellent results, even though our participation was rather casual. Ultimately, I find myself in Hawaii. Initially, the decision to visit Hawaii was taken with the idea of expanding our horizons, even if our paper was not accepted. However, our paper’s acceptance at the ICML conference has made this trip all the more meaningful. I look forward to fully immersing myself in this exciting and fruitful journey before returning to Korea.
And on that note, I conclude my updates from Hawaii🏝!


Our audio technologies support various devices and platforms.
