Thanks Apple, Welcome Vision Pro! (ft. Spatial Computing & Spatial Audio)Thanks Apple, Welcome Vision Pro! (ft. Spatial Computing & Spatial Audio)
(Writer: Henney Oh)
ONE MORE THING!
23년 6월 WWDC, Apple이 드디어 “One More Thing”을 외치며 Vision Pro 라는 이름으로 Spatial Computing Device를 선보였습니다! ‘VR HMD’ 라거나 ‘AR 글래스’ 라고 부르지 않고, “Spatial Computing“ 기기라고 정의한 것부터가 애플 답습니다.
2014년, 가우디오랩은 VR 시장에 첫 발걸음을 들이며 회사의 성격(그리고 목적하는 시장)을 The Spatial Audio Company for VR로 정의했습니다. 그래서 그동안 사람들에게 가장 많이 들었던 질문 중에 하나가 바로 “언제쯤 VR 시장이 올 것 같나요?”가 아니었나 싶습니다.
이 빈출 질문에 대한 제 답은 영리하게도 혹은 비겁하게도, “애플이 VR 기기를 내놓는 날이요”이었죠 😎
그리고 드디어! 그날이 오고야 말았습니다. 꼭 10년 만이네요.
(애플은 Vision Pro를 2024년 봄에 출시한다고 발표했습니다)
이번 WWDC의 애플 키노트에서는 기기 소개 세션의 상당한 비중을 할애해 Vision Pro에 들어간 Spatial Audio를 설명하고 있습니다. 애플은 언제나 눈에 보이지 않고 그 차이를 사용자가 쉽게 인지하기 어려운 오디오에 참 많은 공을 들입니다. 오늘의 애플이 있게 만든 그 출발선에 바로 iPods라는 오디오 기기가 있었다는 사실!
[사진: Spatial Audio 기능이 내장된 Apple Vision Pro의 Dual Driver Audio Pods (스피커)]
Spatial Audio, NICE TO HAVE → MUST HAVE
애플의 Spatial Audio는 지난 2020년 AirPods Pro에 처음 적용되며 선을 보였습니다. 그 당시 제 주장 또한 “이 Spatial Audio는 미래에 애플이 내놓을 VR/AR 기기를 위한 사전 포석이다”였지요.
조그만 윈도우 안의 2D 화면을 보는 스마트폰(또는 TV)에서의 Spatial Audio 경험은 Nice-to-have(있으면 좋은, 멋진) 라면, VR 환경에서의 Spatial Audio는 Must-have로 바뀝니다. 가상 환경 속, 나의 뒤편에서 날 부르는 강아지의 소리가 눈앞 쪽에서 들려선 안되겠지요.
앞서 다른 포스트(링크)에서 VR Audio, Immersive Audio, 3D Audio, Spatial Audio, … 표현은 달라도 그게 그렇게 다르지 않다고 말씀드렸었습니다. 필요나 시장의 성격에 따라 부르는 이름이 다를 뿐, 3차원 음향을 만들고 재현하는 기술입니다.
애플은 2024년에 Spatial Computing Device를 선보일 것을 준비하며, 그 5년 전 3D 오디오 기술을 AirPods에 적용하며 이미 Spatial Audio라고 불렀다고 하면 억측일까요?
Mono → Stereo → Spatial, 소리 인지 과정의 변화
애초에 사람은 실제 환경에서 소리를 3차원으로 인지합니다. 즉, 지금 옆자리 동료의 키보드 타이핑 소리가 나의 왼쪽 측면에서 나는지 뒤쪽 아래에 있는지를 구분하여 듣는 것이죠. 어려서부터 고도로 훈련된 우리 청각기관과 두뇌의 Binaural Hearing 스킬 덕분에 2개의 센서(양쪽 귀) 만으로 그것이 가능하지요. 따라서 스피커와 헤드폰으로 재생되는 모든 소리도 3차원으로 재현하는 것이 이상적입니다.
그러나 우리는 스피커, 헤드폰/이어폰, 통신 기술, 저장 기술 등 기기의 제약과 기술의 한계로 2D(스테레오) 혹은 1D(모노)로 소리를 저장, 전송, 재생하는 것에 오랜시간 길들여져 왔습니다. 강연장에서 연사가 마이크로 발표를 하는 동안 그 목소리는 천장에 달린 스피커를 통해 나오는 상황에 놓여본 적 있으시죠? 눈앞에 보이는 모습과 들려오는 소리, 즉 Visual cue와 Sound의 위치가 지극히 맞지 않는 상황에서도 우린 이상하다고 생각하지 않고 적응을 합니다. 대형 스피커로 수만 명의 관객에게 소리를 내보내는 공연장의 경험도 마찬가지입니다(무대 위 가수의 위치가 아닌, 벽에 달린 스피커에서 소리가 나는 것이 공연장의 경험이죠). 적응과 학습 역량이 뛰어난 우리 인류는 그렇게 제공된 소리도 이상하다고 생각하지 않고 살아왔습니다. 심지어 그런 소리들을 오랫동안 듣다 보니, 그게 더 좋게 들리는 학습 효과까지 덤으로 얻게 되었습니다.
일례로 일종의 공간 음향 포맷 중 하나인 Atmos Mix 음악들이 기존의 Stereo Mix보다 안 좋게 들린다는 평이 많습니다. 우리가 듣는 대부분의 음악인 스튜디오 레코딩 음원으로는 Stereo가 시장 표준으로 너무 오랜 기간 사용되었고 우리는 거기에 익숙해지게 됐죠. 다만, 과거 사례를 비추어 보면, 모노에서 스테레오로 넘어갈 때에도 많은 아티스트와 사용자의 저항감이 있었다고 하니, 언젠간 우리가 Spatial Audio Mix에 더 익숙해질 날도 올 수는 있겠지요.
공간음향의 완성에 진심인 애플, 그 결과가 Vision Pro
Vision Pro를 쓰면 스타트랙의 홀로덱과 같이 원격 회의를 하는 상대방이 마치 내 방에 같이 앉아서 대화를 하는 것 같은 경험을 제공할 수 있습니다. “Being There” 혹은 “Being Here” 경험의 끝판왕이 될 것입니다. 그리고 이를 위해 Spatial Audio 는 필수(Must-have)입니다. 내 눈앞에 있는 상대방이 정말 여기에서 얘기하는 것처럼 소리가 들려야 우리 뇌에 Place Illusion이 일어나기 때문에요. 고개를 돌리면 소리의 위치가 그에 맞게 바뀌기까지 해야 하죠. *Binaural Rendering을 기본 기술로 하는 헤드폰용 Spatial Audio가 바로 그 기능을 해줍니다.
* Binaural Rendering은 무엇이고 어떻게 쓰이냐면요…
Vision Pro와 같은 Spatial Computing Device(VR, AR을 통칭하여)은 1인용 Display 기기입니다. 내 눈앞에 오직 나만을 위한 영상을 소비한다는 의미에서요. 따라서, 스피커가 아닌 헤드폰으로 소리를 재생하는 것이 필연적이죠. 헤드폰을 통해 Spatial Audio를 실현하는 원천기술이 Binaural Rendering입니다. “Binaural”은 어원 그대로 “두 개의 귀를 가진”의 의미이고, 사람은 2개의 귀(소리 수음 센서) 만으로 귓 바퀴와 우리 몸을 타고 들어오는 소리의 회절, 음영 현상 등을 이용하여 전, 후, 좌, 우, 상, 하 등 사방 팔방의 소리 방향을 인식합니다. 이 원리를 시뮬레이션해서 헤드폰을 통해 재현하여 3차원 공간에 소리를 정위하는 것이 바이노럴 렌더링이지요.
소리가 마치 이 공간에서 나는 것처럼 하기 위해서는 실제 그 자리에서 나는 소리가 우리 귀에 도착하는 경로(소리는 우리 주변의 벽, 소파, 천장 등의 사물을 만나면 일부는 흡수되고 일부는 반사되는 성질을 가지고 있습니다)를 모두 알고 그에 맞는 경로 모델링을 모두 해줘야 합니다. Vision Pro에는 이 일을 수행하기 위해 Audio Ray Tracing 기술까지 적용했다고 하죠. 엄청난 Computing 과정인데, 애플 실리콘(M2 & R1)의 승리라 할까요? 어쨌거나 그만큼 애플은 공간 음향의 완성에 진심이라는 얘기입니다.
[사진: Audio Ray Tracing - WWDC 2023, Vision Pro Keynote 중에서(영상 캡쳐)]
Thanks Apple, Welcome Vision Pro!
가우디오랩은 Works(사운드 엔지니어들이 기존의 음향 저작 환경 - e.g. Pro Tools - 위에서 VR 360 영상을 위한 Spatial Audio를 손쉽게 편집하고 마스터할 수 있는 저작 툴), Craft(Unity/Unreal 등의 게임 엔진으로 제작되는 VR 콘텐츠에 Spatial Audio를 입힐 수 있는 저작 툴), Sol(이렇게 제작된 콘텐츠를 HMD나 스마트폰 등에서 Head-tracking 정보를 더해 실시간 Spatial Audio 경험을 제공하는 바이노럴 렌더링 SDK)을 이미 2016-2017년에 순차적으로 선보이며, Spatial Computing/VR/AR을 위한 완전한 Spatial Audio 소리 경험의 끝점을 찍었습니다.
[사진: VR Audio = Gaudio 키노트 중]
2018년 이후 VR 시장에 혹한기가 오면서 많은 관련 기술 회사들이 문을 닫았습니다. 그 혼돈 속에서도 가우디오랩은 해당 기술을 기존 시장/제품에서 활용할 수 있도록 피벗하여, 아래와 같은 기술들을 선보이며 꿋꿋이 때를 기다리며 기술을 더욱 연마하였습니다.
스마트폰/2D 스크린의 (라이브) 스트리밍 환경에서 일반 헤드폰 만으로 Spatial Audio를 경험할 수 있도록 만든 BTRS(Link, Works의 후신)
이어 버즈, 헤드폰에서 일반 Stereo 신호에도 Spatial Audio 경험을 선사할 수 있도록 하는 GSA(Link, Sol의 후신)
가우디오랩 실험실에는 차량 환경을 위한 Spatial Audio, 스테레오 스피커 또는 사운드바를 위한 Spatial Audio, 극장에서의 Spatial Audio 등 ‘The Original Spatial Audio Company’(공간 음향 종주 회사)'라는 위상에 맞는 다양한 Spatial Audio 제품과 혁신 기술들이 차곡차곡 쌓이고 있습니다.
참, 곧 열리는 AES 2023 International Conference on Spatial and Immersive Audio (August 23-25, 2023, University of Huddersfield, UK))에서는 가우디오랩 실험실의 최근 연구 성과인 ‘Room Impulse Response Estimation in a Multiple Source Environment’라는 논문을 발표합니다.
애플이 사용하는 Audio Ray Tracing 과 같은 별도의 장비 대신에 공간에 이미 존재하는 여러 소리(이를테면 상대방의 목소리)로 부터 해당 공간의 음향 특성을 자동으로 인식, 추출하여 Spatial Audio에 적용하여 몰입감을 더욱 올릴 수 있는 AI 기술에 대한 내용입니다.
스마트폰, TV, 극장 등 2D 스크린 환경에서의 Spatial Audio는 맛보기편. 가우디오랩의 Spatial Audio 기술들을 맘껏 펼칠 Spatial Computing 시대의 도래가 벌써부터 설레입니다.
오래 기다렸다, Thanks Apple, Welcome Vision Pro!
2023.07.25 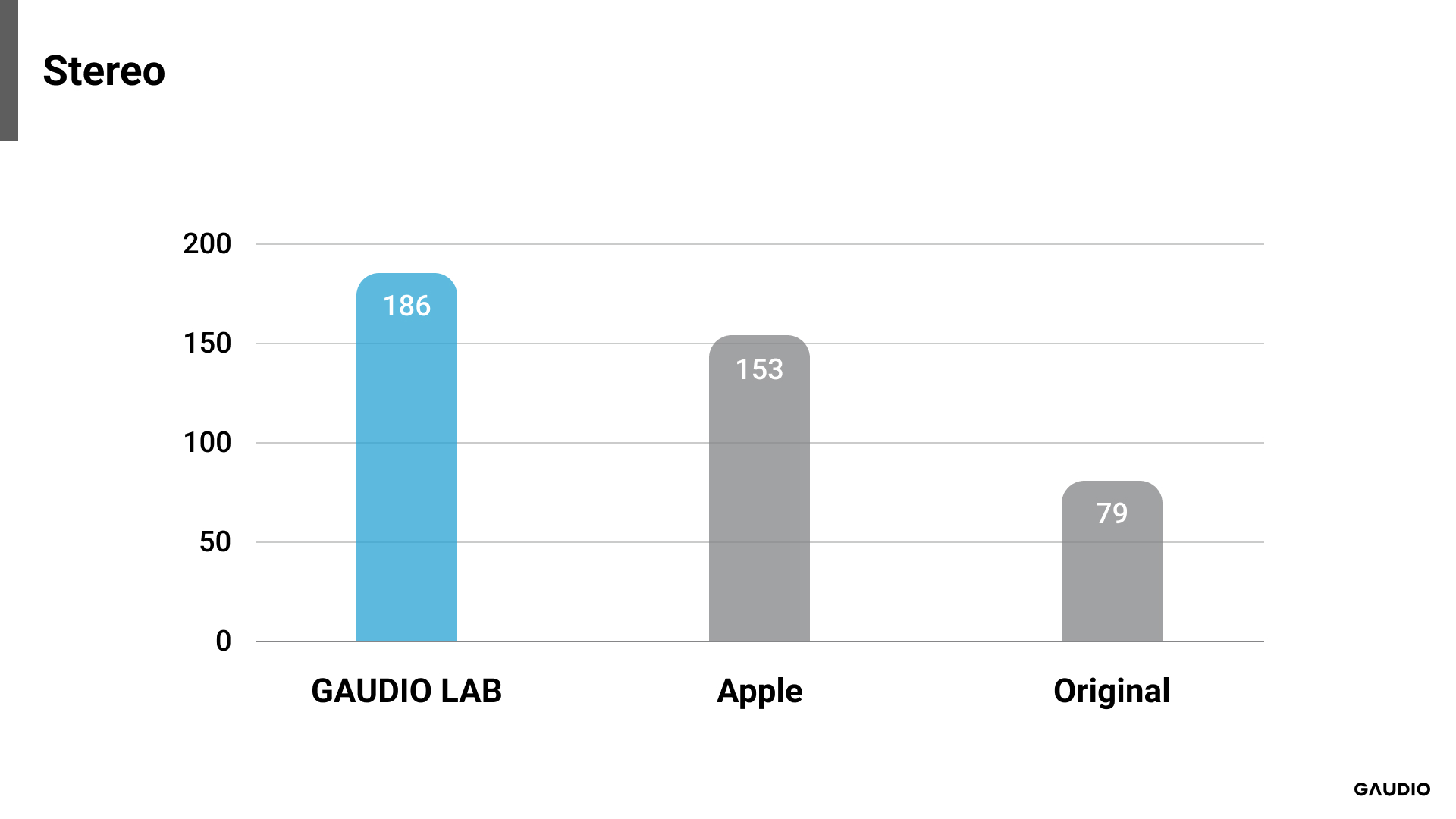
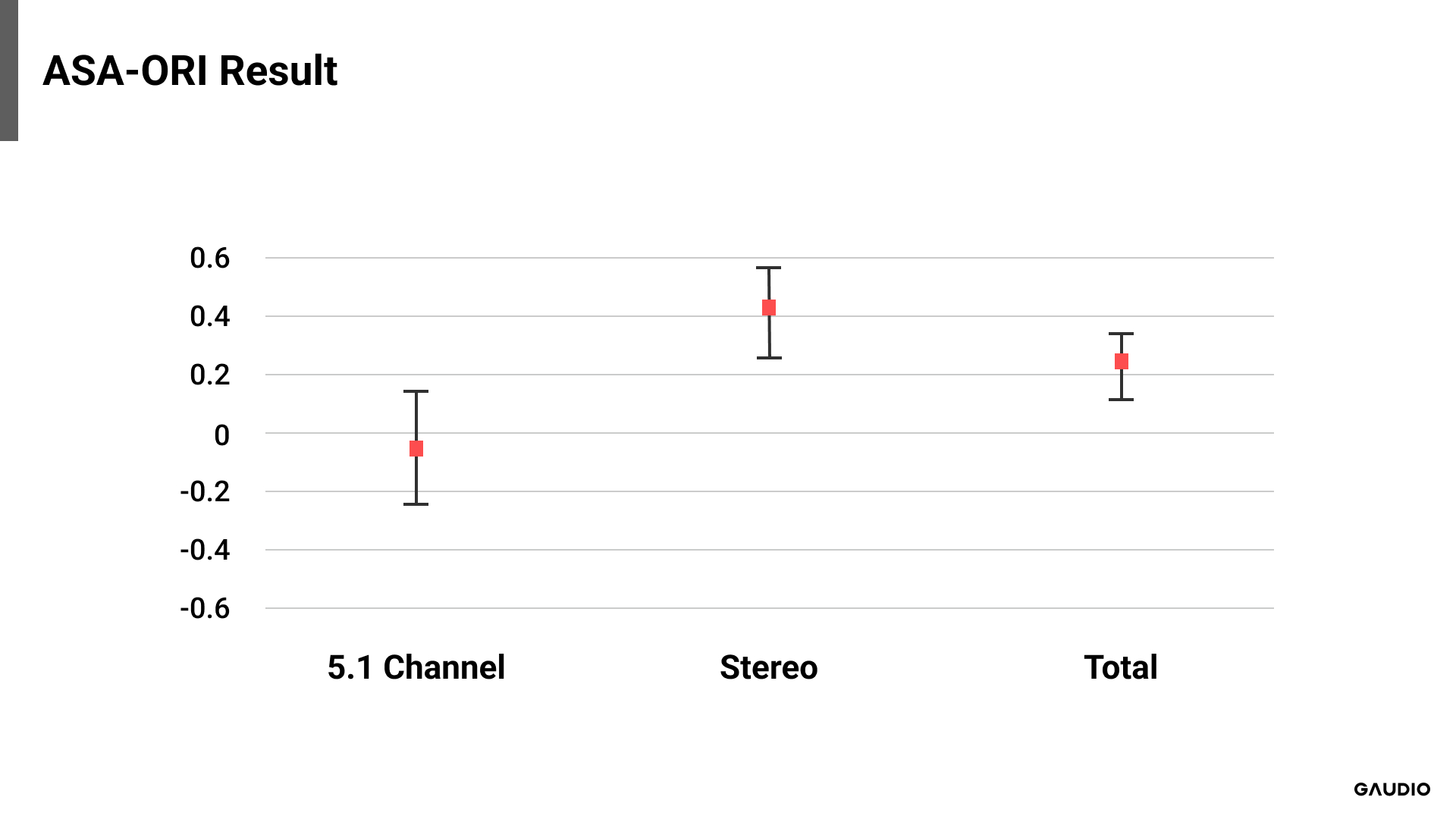
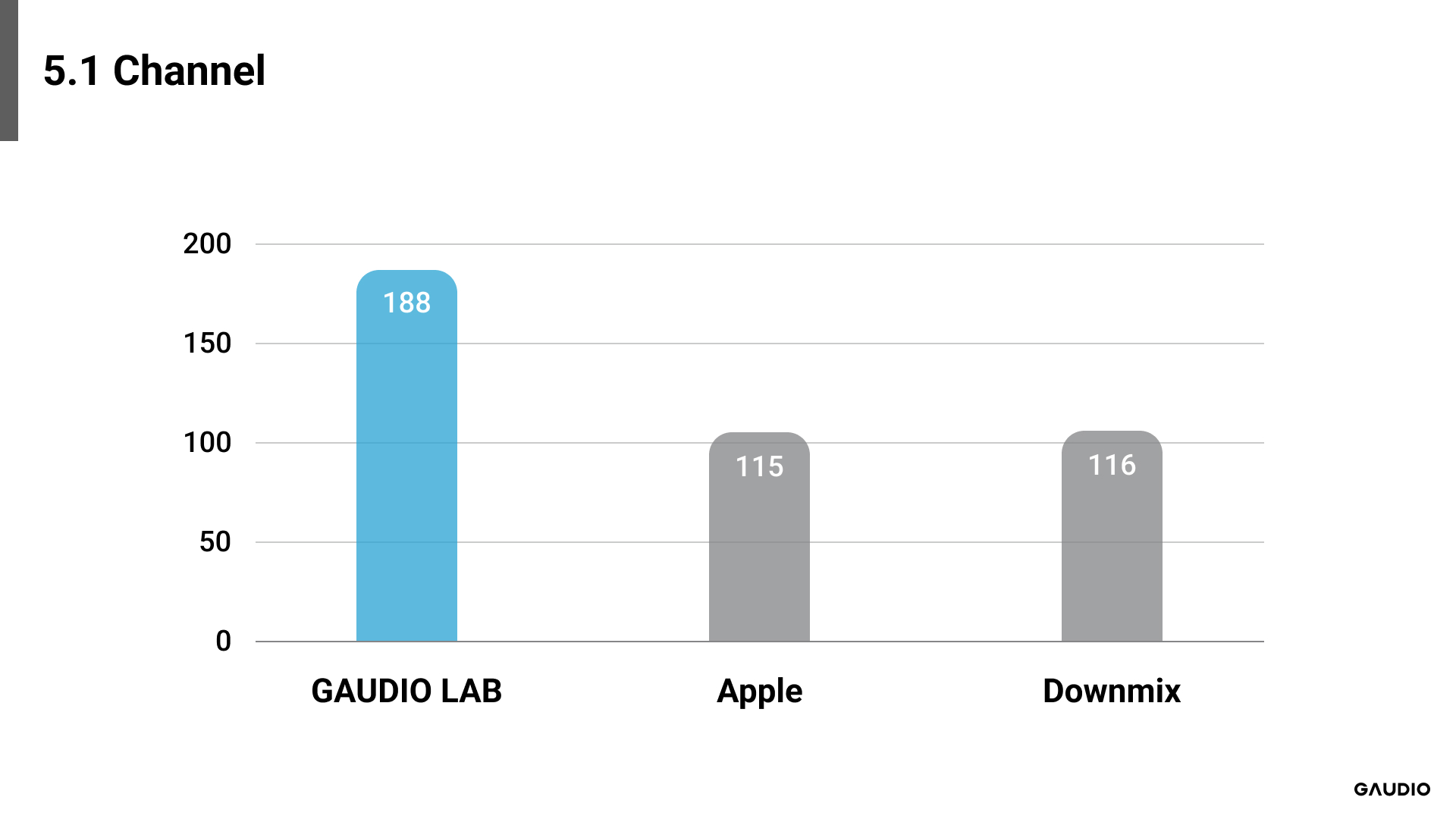 [그림 2: 5.1 Channel 결과]
[그림 2: 5.1 Channel 결과]
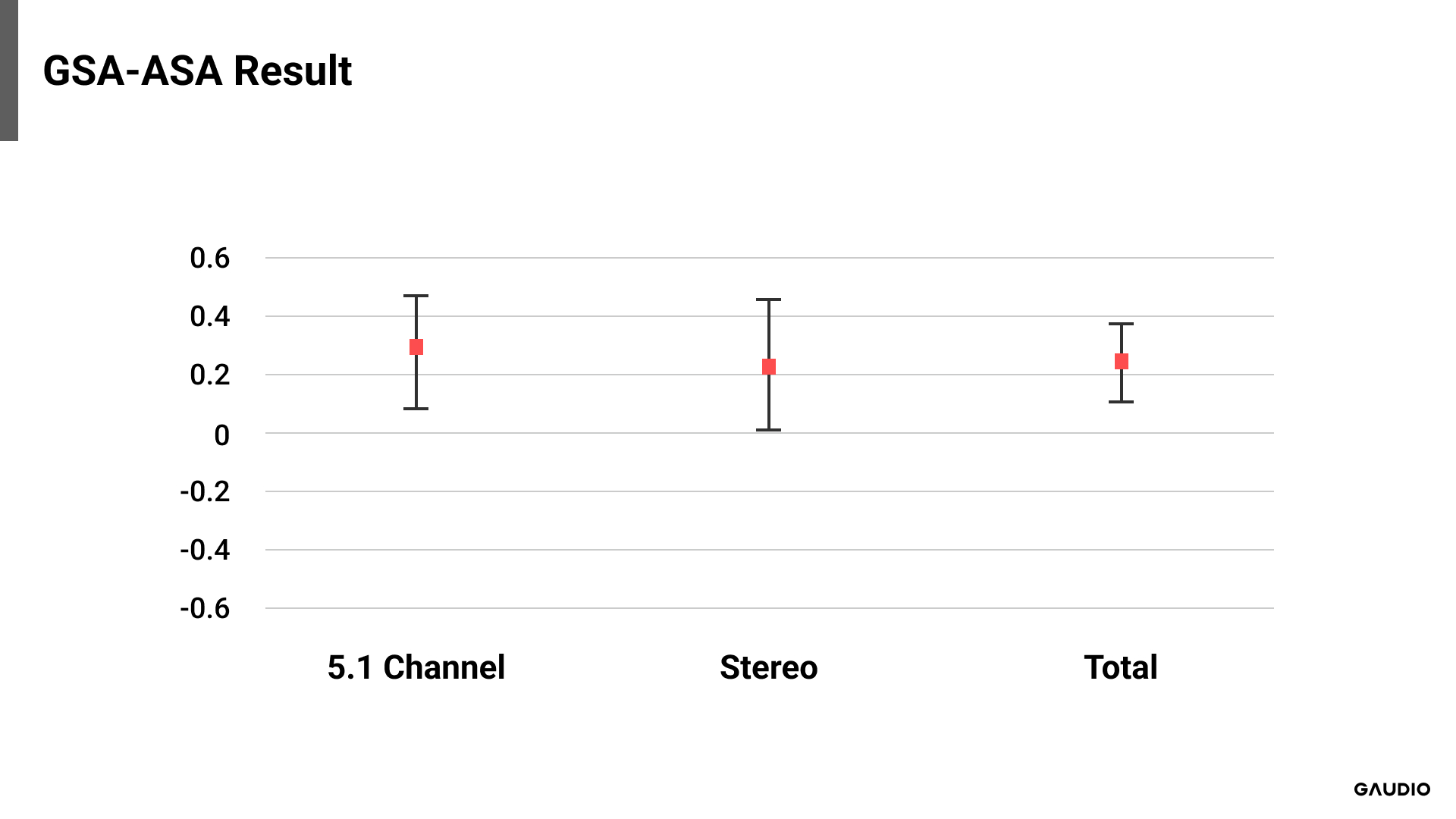
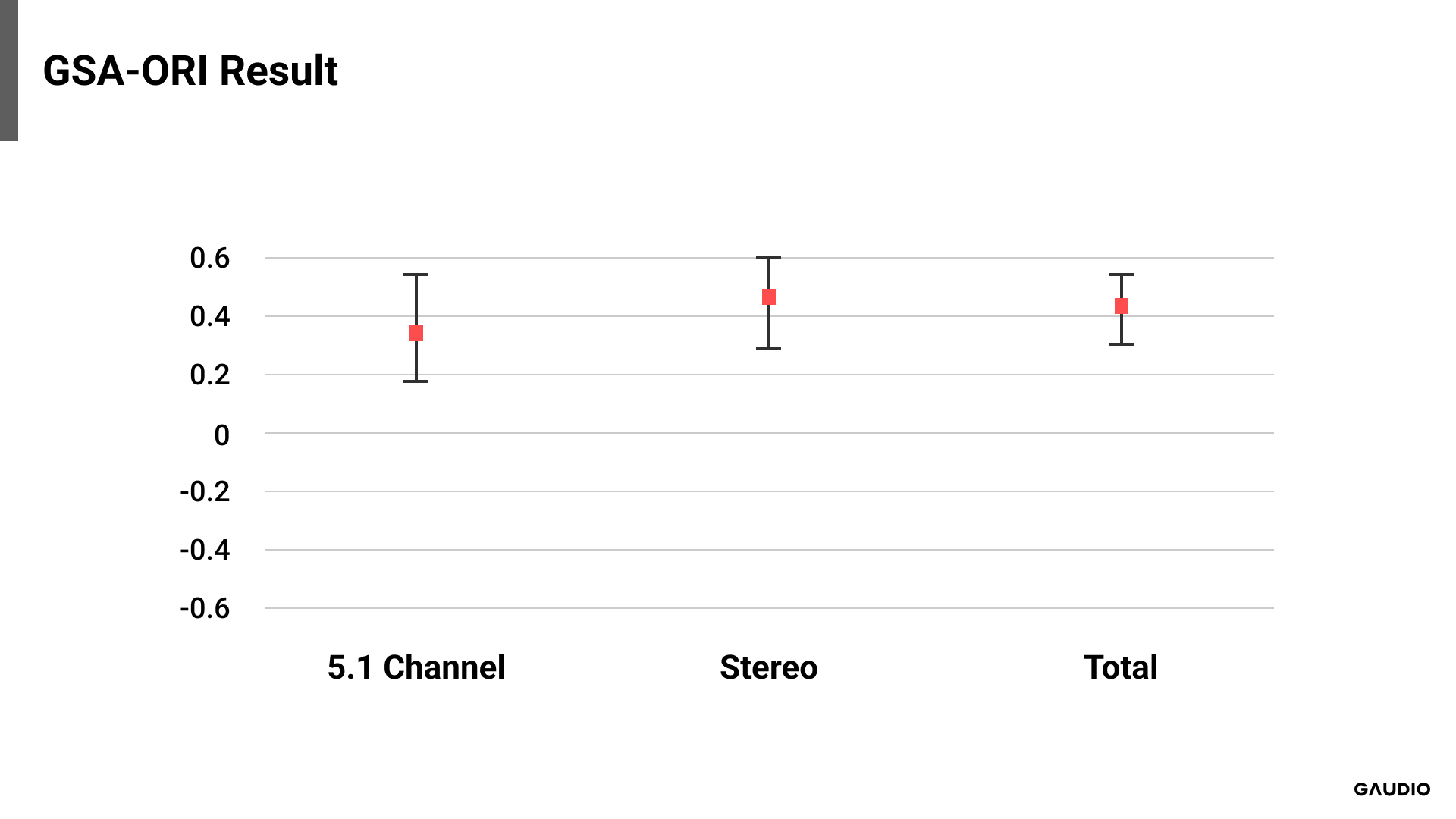 [그림 5: GSA -원본 결과 비교]
[그림 5: GSA -원본 결과 비교]