Reinventing music with VR: Personal and Interactive audio in full 3D space
Reinventing music with VR: Personal and Interactive audio in full 3D space
05/24/2017
Early critics thought jazz totally ruined the music that came before it. And that rock and roll did after that. Don’t even get started on rap and hip hop. New musical styles frequently face fierce criticism when they first hit the scene, but they bravely fight on to drive music, style, and culture forward in the face of those who oppose them. New technologies also tend to receive a comparably warm welcome. Well, keep your torches and pitchforks at the ready, because you may not like what’s coming next.
3D audio and virtual reality can totally change the way that people experience music. VR headset users have the freedom to look wherever they want. This actually isn’t anything new — you’ve always had the freedom to look wherever you want. The only thing that’s changed with VR is that now instruments can truly be placed all around you. In traditional stereophonic setups or multi-channel loudspeaker mapping scenarios, sounds are only located in front of the stage or screen to correlate with a person’s natural viewing angle. Even if the speaker configuration is increased to 5.1 or 7.1, the speakers at the back only create a general sense of ambiance, since there’s no corresponding visual source behind the audience. We briefly touched on these ideas in this article featured on AR/VR Magazine.
Placing sound sources in full 3D space not only increases variety, but it can also increase localization accuracy by freeing sources from a restrictive physical speaker configuration. However, just because sounds can be placed anywhere does not mean that they should be placed everywhere. This reinvented music can be compelling, but it won’t be without some challenges of its own.
Positioning sound sources in full spherical space
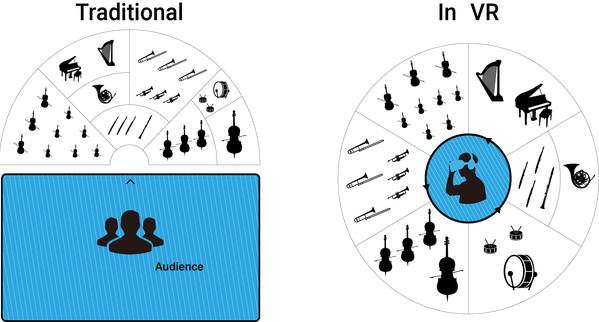
It’s one thing to talk about it on such a high level, but what would this new experience actually feel like? Picture yourself at the central point of a fully three-dimensional space, while performers and instruments surround you in every direction imaginable. In this vision, you are more immersed in the experience than ever before, and it overcomes the limitations of conventional music creation and reproduction, which is at best panned 180° in front of you.
Listening to this kind of music in spherical space is no longer a fantasy thanks to VR, specifically if the audio is from an object-oriented mix. In an object-oriented mix, sound sources — instruments, vocals, ambient sound or any combination — can be placed anywhere in a 3D space with azimuth, elevation and distance information for each object. Each of these sound points are then rendered and projected through “virtual loudspeakers.” There can be as many virtual speakers as there are objects, as long as the right format is used. You may have thought you were listening to “surround sound” in the past, but sound objects were never actually surrounding you. The promise of full three-dimensional sound is only truly fulfilled in VR.
An expanded 3D canvas requires more than just matching image and audio
Before all else, sound must be spatialized accurately. The audio has to match the image as closely as if the sound source was attached to the visual object moving about the scene. The process of incorporating that positional data to sound sources is key, and since a VR headset user’s head orientation should be always be accounted for, the need for a good renderer is paramount. These post-production and consumption tools for this new medium are vital building blocks in creating the experience, but creators must wield them correctly if they want any chance of creating a transformative experience.
The industry is ready to graduate from simply matching the audio with the visuals. The next level of our VR education will be attempting to place sounds in every position imaginable. If we look again to history as our template, instrument placement in orchestras has been fine-tuned over hundreds of years. We will likely need a similar approach for our virtual canvas, which is expanded 360 degrees horizontally and 360 degrees vertically beyond the physical dimensions of a stage in real life. These new 720 degree settings are the Wild West of the musical frontier, and we’ll need a new set of operating guidelines to make the most of them.
The new guidelines should help artists use the creative tools correctly by addressing their use with the added dimension of space to consider. In VR, a song is not just about framing the timing of the elements, but about spatially framing them as well. Composers used to only need to care about each instrument’s pitch, loudness, and timing. They still have to care about those, but now they also have to take each instrument’s “virtual location” into consideration. Sheet music will be ineffective since three-dimensional data must be attached to each sound. Where to place a sound is totally up to them, which presents an unprecedented challenge along with unprecedented opportunities for inspiration. Instruments can be placed near each other to balance the harmony or totally separate to strategically convey a certain intention.
Many questions have been raised about instrument location, but they can be asked again regarding the listener. If it is an interactive VR piece where six degrees of freedom is possible, the listener’s position can change. This leaves the creator with plenty of power and a difficult dilemma. Should they give the audience the same unrestricted freedom they’ve become accustomed to in VR at the risk of missing the artist’s intent? Or should they use cues and restrictions to deliberately designate the listener’s position? It’s clear that these ‘spatial’ aspects are factors to consider during the creation stage well before the music ever reaches the audience’s ears.
Exploiting human auditory perception
You might not know it, but you’re already wired to take advantage of some elements that are pretty unique to the VR music model, and the shift from a channel-oriented approach to an object-oriented one further opens the door for a more personal and interactive experience. In one example of this, a fan who loves drums could potentially hear the drums louder than any other instrument in the song. This sounds a little farfetched, but there have already been steps to explore this phenomenon. In 2010, the Moving Picture Experts Group expounded on a signal compression method that details how a listener can manipulate sound to hear one audio signal over another on the device. This is now referred to as MPEG Spatial Audio Object Coding (SAOC).
Listeners in VR can control their sound experience depending on personal preference even without SAOC simply by looking at a specific item, as long as the mix is delivered to the device in an object-based format. We could conceivably take this idea one step further and make looking at the object fully interactive — if a VR headset user looks at one object long enough, it would indicate that the user wants to hear it up close, and the loudness of the object would increase as a result. I might like to watch Imagine Dragons music 40° to the right to listen to the guitar more but you might like 120° to the right so you can hear the vocals louder.
VR is giving this powerful option of controlling which sound you want to hear to the user — making audio more personal and truly interactive. But do these ideas of auditory individualism have any foundation outside of VR? How can you hear one sound more than another just by looking at it?
Psychoacoustic principles can help answer some of these questions, and one principle that will be prominent in VR environments is Binaural Masking Level Difference. BMLD explains that you can hear a smaller sound over a larger one as long as they are spaced out. Let’s say there are a loud bell and a softly chirping bird. If they are located in the same position as each other, you can’t hear the bird, a concept called spatial masking. However, if they are located in different positions, that same quiet bird is spatially unmasked and becomes audible.
Meanwhile, another psychoacoustic theory commonly known as the “cocktail party effect” will also be influential. If you’ve ever found yourself in a loud and crowded room, but able to carry on a conversation with someone very interesting to you, you have been the beneficiary of this phenomena. If you can determine the direction and thus the location of a sound object, you can single out its sound to hear it more clearly than the rest. Using the same objects in the above illustration, you would be able to hear the bird over the bell if you know its direction and pay more attention to it, as long as bird and bell are spaced out.
We have seen proof of both BMLD and cocktail party effects thanks to our recent 360 music video experiment with Jambinai. In the scene, there are several musical instruments, or objects, placed in separate locations. If you pay attention to one instrument (object), the others blend together into something more like background sound. Now that you are focused on one object, a different perceptual loudness is delivered to you, and you can clearly hear that specific object sound. If Jambinai was downmixed into a standard mono mix, you would hear well-balanced sounds for each instrument, but they would lose a significant amount of detail. Since the information for each instrument is preserved in an object oriented mix, a listener can single out each instrument and hear its details. Amazingly, this leads to a different musical experience for each individual, even though the musical piece is exactly the same.
However, this level of customization could be a point of contention because creators ranging from composers, players, sound engineers, producers have mastered their song in a specific way. So some critics will ask “why should the composition be suspect to corruption by the listener?” That’s a fascinating topic for another time. What needs to be understood for now is that it has become easier for a listener to focus on one sound object over another, which is a huge jump from the stereo-oriented era.
Many enthusiasts contend that the balcony, not the middle or the front, is the sweet spot to listen to an orchestra. If you are creating VR content that lets users explore the scene on their own, then finding that perfectly harmonized spot may not be the ultimate goal. We are at the frontier of a new wave of music — an unblazed trail waiting for those VR audio engineers who are brave enough to pave the way forward.
2017.05.24