Audio Quality Evaluation of Spatial Audio Part 1: Designing the Evaluation
Audio Quality Evaluation of Spatial Audio Part 1: Designing the Evaluation
(Writer: James Seo)
My name is James, a specialist in Research and Development for GSA (GAUDIO Spatial Audio). In our previous discussion, we explored the measurement of M2S (Motion-to-Sound) Latency, an indicator of GSA’s responsiveness to user movements. Today, we seek to address the following question: “Is the sound we hear really that good?” Given that GSA is designed specifically for wearable devices such as True Wireless Stereo (TWS) and Head-Mounted Displays (HMD), sound quality is a vital factor. Regardless of its swift responsiveness to movements, it cannot qualify as an exceptional product if the sound quality is subpar. Sound matters!
Methods of Audio Quality Evaluation
Before delving into the evaluation techniques for GSA’s performance, it is necessary to familiarize ourselves with the methods used to assess audio quality.
Various strategies exist for evaluating the performance of an acoustic device or system. A prevalent approach involves measuring performance based on parameters extrapolated from the sound being reproduced. Our prior discussion on the M2S latency measurement serves as a quintessential example. In addition, standardized methodologies such as PEAQ (Perceptual Evaluation of Audio Quality) and PESQ (Perceptual Evaluation of Speech Quality) are commonly used for assessing audio/voice codecs’ efficacy. Typically, these techniques analyze individual sounds to calculate Model Output Variables (MOVs), elements that influence perceptual quality. The final quality score is derived from a weighted summation of these values. This type of evaluation is termed Objective Quality Evaluation. These evaluations involve feeding an acoustic signal into software or a device and then calculating the final quality score, a process praised for its efficiency due to the relatively short time required.
However, these standardized objective evaluation methodologies have their limitations. Since they are designed to assess the degree of degradation in the quality of the signal under test (SUT) relative to a reference signal, they become impractical in the absence of such a reference. This constraint is inherent in these standardized methodologies, given they were initially developed to evaluate codec performance.
Another evaluation strategy is the Subjective Quality Evaluation method. Here, the evaluator listens to and compares the audio source under evaluation, judging its quality based on personal criteria. An example of this evaluation method is MUSHRA (Multiple Stimuli with Hidden Reference and Anchor). Nonetheless, as personal standards can vary significantly, obtaining reliable results necessitates a large pool of evaluators, which presents a logistical challenge. Besides the need for numerous evaluators, this approach can be both time-consuming and expensive since each evaluator must personally listen to and assess the sound. Lastly, as implied by its name (Hidden Reference and Anchor), it shares the limitation of being applicable only when a reference signal is available.
We are now in the process of choosing how to evaluate the GSA. Given that spatial audio signals do not have a suitable reference signal, we cannot employ objective evaluation methods like Perceptual Evaluation of Audio Quality (PEAQ). Similarly, Multiple Stimuli with Hidden Reference and Anchor (MUSHRA), a subjective evaluation method, is not applicable for the same reason. Moreover, conducting a subjective evaluation based solely on the output signal of the GSA presents significant challenges for evaluators and can make it difficult to produce reliable results.
After careful consideration, we’ve decided to compare the GSA with familiar, widely-used solutions that have a well-established reputation for quality. Although there were several spatial audio solutions that could have been considered, increasing the number of comparative systems also expands the quantity of signals requiring comparison. This circumstance could put significant pressure on the evaluators and potentially reduce the reliability of the results. As a result, we chose to limit our comparison to Apple’s Spatial Audio (hereinafter referred to as ASA), ensuring a focused one-to-one comparison.
Design of Subjective Quality Evaluation
(1) Preference Testing through Paired Comparison
Our primary comparison method is a preference test performed using a paired comparison. This process involves presenting two signals in a random sequence and determining a preference. The preferred system is awarded a score of +1, while the non-preferred system receives a score of 0. This method can be likened to asking someone: “Who do you love more, Mom or Dad?” We’ve adopted the Double-Blind Forced Choice technique for this evaluation, which means the evaluators cannot know whether the sound they are hearing has been rendered by ASA or GSA. Since evaluators simply listen to signals and randomly select a preference from two options (A or B), intentional bias can be effectively minimized.
(2) Selection of Sound Excerpts
The next step involves selecting the sound sources for evaluation. Since the performance of a solution can vary based on the characteristics and format (number of channels) of a sound source, the results may differ depending on which sound source is used for evaluation. Initially, we differentiated and selected sound sources based on 2-channel stereo and 5.1 multi-channel. Although 2-channel stereo is the most common format encountered by users in everyday environments, we also included 5.1 channel sound sources because some films and music sources are mixed into 5.1 channels to enhance the sense of spatiality.
For stereo sound sources, we selected one song from each of various music genres, and added a few movie clips in stereo version, resulting in seven sound sources in total. We also selected seven sound sources with various characteristics, including films, music, and applause, for multi-channel audio. Each chosen sound source was trimmed to a length of 10-15 seconds, considered to be the most appropriate duration for subjective evaluation.
(3) Generation of Evaluation Signals
The primary goal of this evaluation is to measure the quality of Spatial Audio that dynamically adapts to user movements. Ideally, we would render each evaluation audio source to reflect actual user movements. However, due to the exclusivity of Apple’s Spatial Audio (ASA) within the Apple product ecosystem, we encountered limitations in constructing the ideal experimental environment. It was impractical to secretly implement alternative Spatial Audio renderers on devices such as the AirPods Pro or iPhone for evaluation purposes. As a result, we resorted to creating signals separately, rendering them for fixed head orientations, and selecting front-facing orientations that users encounter most frequently.
Another challenge is capturing sound from ASA, given it only operates within Apple’s ecosystem. Fortunately, at Gaudio Lab, we managed to acquire filters associated with ASA. Despite current iOS updates blocking this route of acquisition, there was a period when we could capture signals transmitted to True Wireless Stereo (TWS) devices like the AirPods Pro. We accomplished this by activating the Spatial Audio feature and playing the audio source.
Although it is feasible to play the desired audio source from an iPhone and capture the actual rendered signal, using specific signals such as a swept sine can also directly yield ASA’s filter coefficients. After combining the obtained filter and audio source and replaying it through the AirPods Pro, the sound rendered with Spatial Audio reproduces identically to an actual iPhone/AirPods Pro setup. Alternatively, using an ear simulator equipped with AirPods Pro to capture the response of ASA in its on/off states—excluding the TWS response—also offers a method to obtain filter coefficients. However, this approach is somewhat technical and diverges from the main discussion, and thus will not be covered here.
For the listening evaluation, we used the AirPods Pro as the evaluation medium to enable a fair comparison between ASA and GSA. This approach minimizes the impact of variations in quality due to differences in the final playback device, facilitating a more focused evaluation of the renderer’s performance in implementing spatial audio.
In addition, we included original signals that bypassed both ASA and GSA in our comparative analysis. Should the evaluation reveal that both ASA and GSA underperform compared to the original signal, it would render the comparative exercise futile. Reviewing these results offers insights into evaluators’ overall preference for spatial audio against the original signal. We treated a downmixed audio source from 5.1 channels-to-2 channels as the original signal. As a result, the final set of comparative signals for each evaluation audio excerpt is organized as follows.
- GSA vs. ASA
- GSA vs. Original
- ASA vs. Original
(4) Setting for Subjective Quality Evaluation
The setting for subjective quality evaluation, where evaluators conduct their assessments, is outlined below:
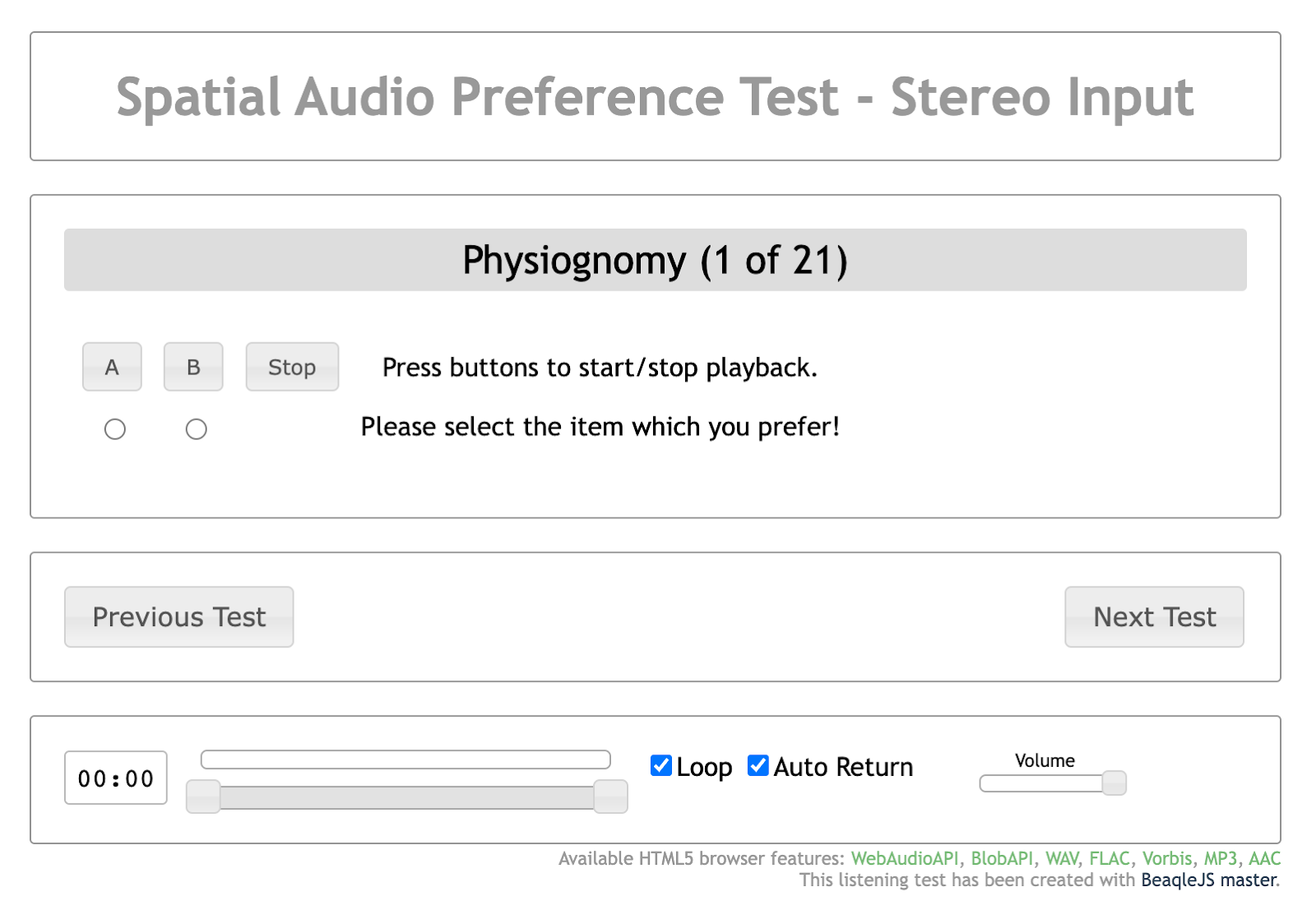
As demonstrated in the figure, evaluators can identify only the name of the evaluation audio excerpt. They are kept unaware of which signals – ASA, GSA, or the original – have been allocated to options A and B. The individuals designing the evaluation are equally unaware of how options A and B are allocated, and they cannot dictate which audio source appears first for assessment. The sequence of the audio sources is randomized by the system, ensuring that their order does not influence the results.
Within this interface, evaluators are tasked to select what they believe to be the superior option between the two presented. Upon making this selection and clicking the ‘Next Test’ button, they proceed to the subsequent evaluation. This procedure embodies the double-blind forced-choice method previously discussed. Evaluators are allowed to repeat specific sections during the assessment of a single audio source without any imposed restrictions. As the evaluation system is web-based and hosted on the Gaudio Lab’s server, it allows for concurrent evaluations by multiple users. Upon the conclusion of each assessment session, the results are stored on the server.
(5) The Evaluation Panel
The current round of evaluations included a total of 20 adults, both men, and women, ranging in age from 20 to 40. Among these participants, 11 were seasoned evaluators with extensive experience in auditory assessments. To incorporate perspectives from the general public, we included nine individuals who lacked specialized knowledge in sound quality evaluation or related technology but displayed a keen interest in activities such as regular music listening.
The result will be revealed in Part 2. Stay Tuned!

Our audio technologies support various devices and platforms.
