Music Generative Model - 박수철 연구원(모두의 연구소)|전문가 초청
가우디오랩에서는 다양한 오디오 기술을 연구개발하여 제품화하고 있는데, 최근에는 AI 모델을 사용하는 제품들도 만들어지고 있습니다.
점점 AI 모델에 대한 효용성이 높아질 것으로 보이는 이 시점에, Music Generative Models에 대한 연구를 진행하신 박수철 님을 모시고 세미나를 진행하였습니다.
박수철님은 4가지 Music Generative 모델에 대해서 소개해 주셨고, 4번째 모델 Music Transformer로 본인이 직접 학습하고 만드신 곡도 공유해주셨습니다.
(1) 개요 : Auto-regressive Model
Music Generation은 한단계 앞까지의 샘플값을 토대로 현재 시점의 샘플값을 예측하는 문제인 Autoregressive Model로 볼 수 있다는 점으로 시작하였습니다.
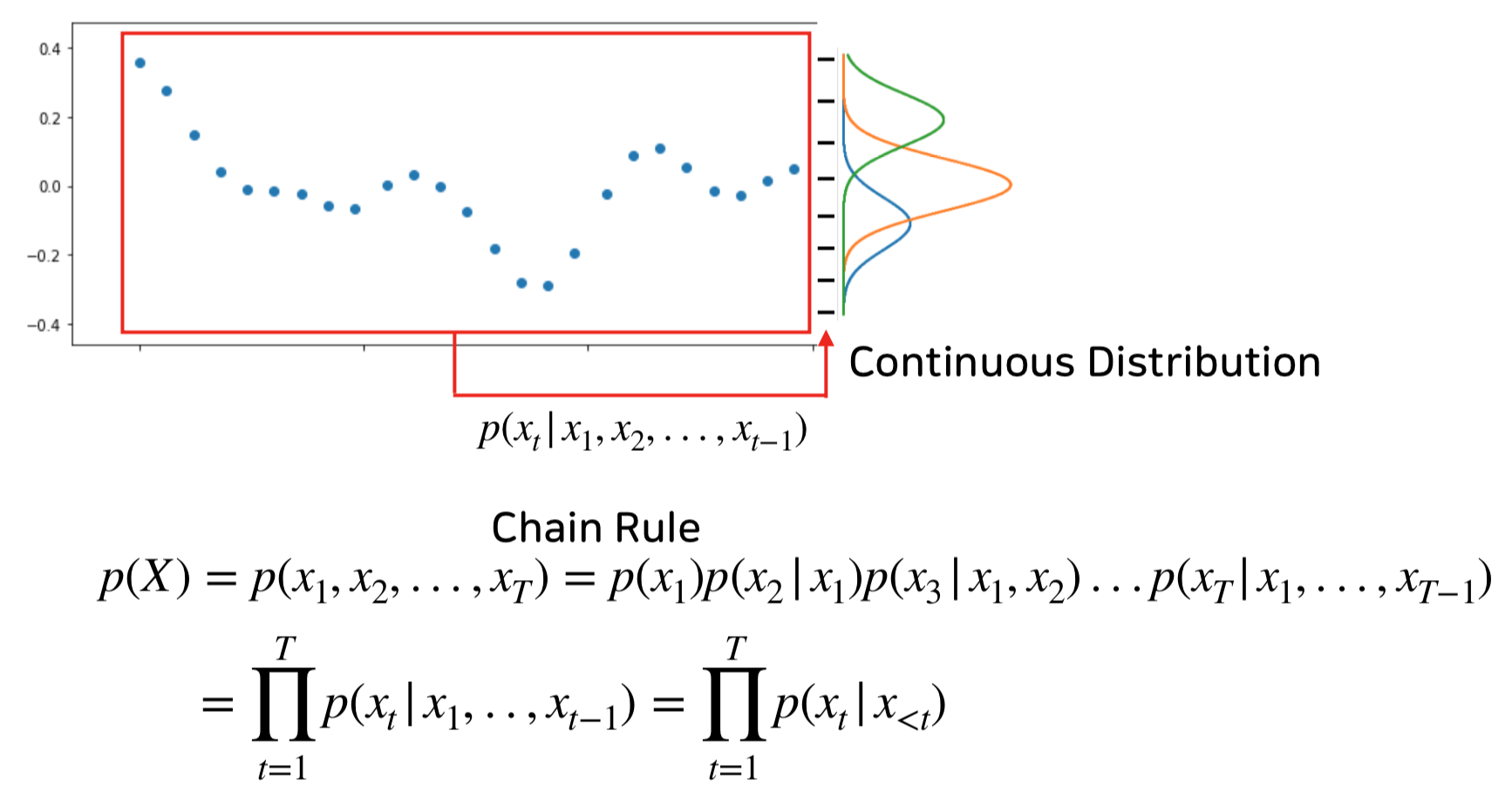
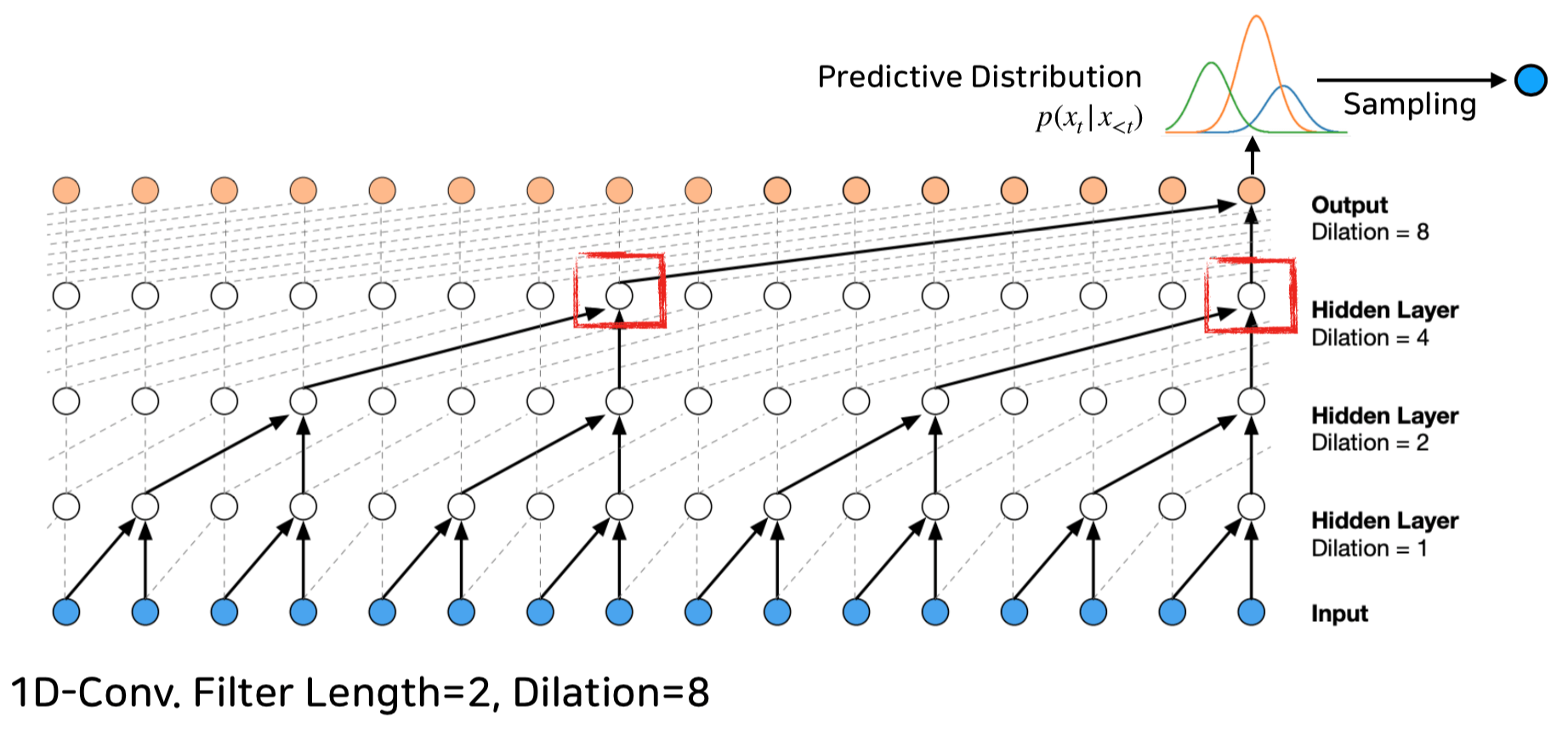
2) 모델 1 : Wavenet – A. Oord (2016)
Wavenet은 Auto-regression의 확률 모델을 Binary Tree와 유사한 구조를 가진 Network를 통하여 Training하는 형태로 구성되어 다음 샘플을 생성해냅니다.
PCM Sample in, Sample out 구조를 가지기 때문에 당연히 Training Database의 음향 특성이 네트워크 안에 흡수가 되고, 트레이닝 된 곡들의 형태를 따라가기는 하지만
곡의 거시적인 관점에서의 맥락을 이해하는 데에는 그 한계를 보이는 Long-term Dependencies Problem을 가지기도 하였습니다.
(3) 모델 2 : Vector Quantised Variational Auto Encoder (VQ-VAE) – A. Oord (2017)
Wavenet의 거시적인 곡의 맥락 해결을 위하여 오디오 신호를 Frame화 하여 해당 Frame의 특성을 Vector로 치환 후, 해당 Vector의 특성을 복호하는 VQ-VAE 기법이 등장하였습니다.
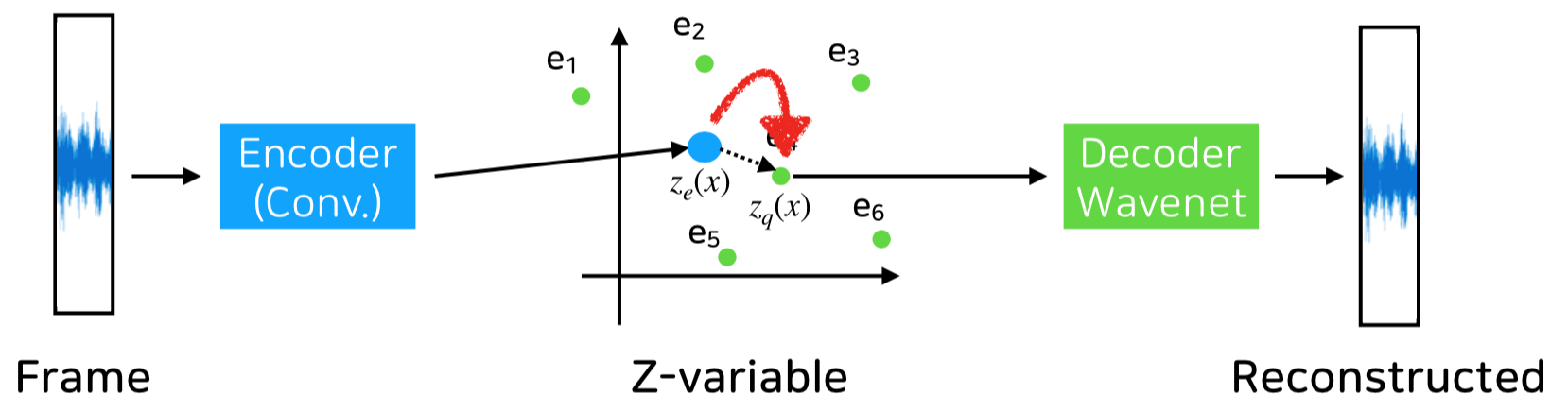
기존의 Wavenet만 사용한 것보다는 Frame에 의한 거시적인 정보를 일반화된 Z-variable 형태의 code북으로 표현함으로써 보다 거시적인 악곡의 형태를 제공함을 샘플 음원을 통하여 확인하였습니다.
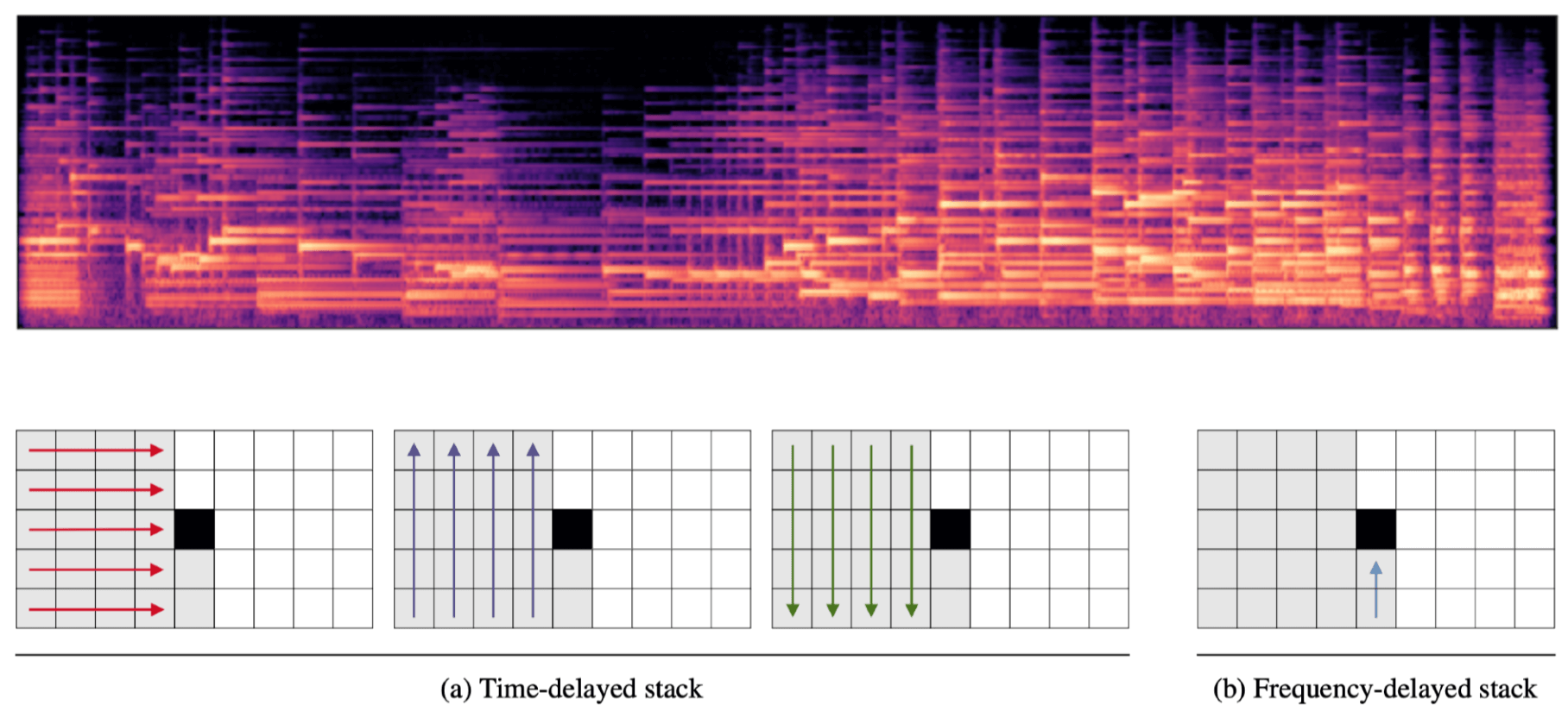
(4) 모델 3 : MetNet – S. Vasquez (2019)
Wavenet이나 VQ-VAE와는 달리, Mel-Spectrogram 상에서, 이전 frame의 spectral information과 현재 frame의 저주파 정보들을 참조하여 LSTM을 겹겹히 쌓는 구조를 갖는 형태입니다.
(5) 모델 4 : Music Transformer – C. Huang (2018)
앞서 설명한 3가지의 모델은 오디오 PCM 신호를 기반으로 Music Generation을 수행하는 반면, Music Transformer는 신호보다 상위 개념인 MIDI 정보를 활용하여 수행합니다.
때문에, 전체적인 곡의 맥락과 구성이라는 점에서 매우 우수한 성능을 보였구요.
보다 세부적으로는, 입력 정보로는 MIDI 데이터가 가진 time(tick), note on/off, velocity 등의 이벤트를 토큰화하여 언어 문장 데이터처럼 활용하고,
현재 예측 지점의 Query 정보와 과거 곡의 MIDI 정보의 Key의 내적을 통하여 참조 여부 및 그 Value를 결정하는 Sparse Attention Model을 활용합니다.
상기 모델들에 대한 느낌은, Music Transformer가 가장 작곡의 관점에 가까운 모델을 가지기 때문에, 가장 자연스러운 곡을 구성하는 것으로 느껴졌고,
Music Transformer가 좀 더 진화하여, 현재는 MIDI로만 구성된 것을 조금 더 나아가 순수 악보 데이터, 연주자의 연주 방식으로 분리하고, 공간 음향 모델을 적용시키게 되면, Beethoven 이 작곡했을 법한 새로운 소나타를 Vladimir Horowitz가 Carnegie Hall에서 연주한 공연 까지 생성하는 날이 그리 멀지 않은 것 같습니다.

