Spatial Ear Training : Localization
Introduction
당연한 말이지만, 우리가 사랑하는 사람의 목소리, 아름다운 음악 등 세상에 존재하는 소리를 들을 수 있는 이유는 바로 두 귀를 가지고 있기 때문입니다. 똑같이 생긴 사람이 없는 것처럼, 귀 또한 사람마다 모두 다르게 생겼습니다. 그런데도 어떤 소리 이벤트가 발생했을 때 귀가 중요한 큐(cue)들을 인지하는 과정은 사람마다 거의 유사합니다. 이는 귀를 통해 전달되는 소리를 뇌가 열심히 트레이닝한 결과로도 볼 수 있습니다. 이번 글에서는 숨 쉬는 것 만큼이나 당연해서 평소에 생각해보지 않았던, 귀가 소리를 듣는다는 것에 대한 재미있는 실험을 소개해드릴려고 합니다. 그중에서도 VR과 AR이 점점 일상생활 속으로 들어오고 있는 이 시대에 가상현실에서 중요한 요소로 여겨지는 소리의 방향 훈련에 대해 살펴보겠습니다.
청능 훈련 ( Auditory training)
특정 분야의 전문가들은 훈련(training)을 통해 특정 감각을 강화합니다. 예를 들면, 바리스타나 소믈리에는 다양한 향을 가진 아로마 키트 (어떤 키트는 144가지 향이 있다고 합니다) 를 이용해서 후각을 강화합니다. 그런데 귀를 트레이닝한다?! 이 생소한 이야기는 정말 가능한 일일까요? 만약 가능하다면, 어떤 부분을 어떤 방법으로 훈련할 수 있을까요? 바로 말씀드리자면, 귀는 트레이닝이 가능합니다. 어떤 소리를 듣는 것에 대해 분명한 목적을 가지고 주의를 기울여서 그것의 소리를 많이 경험하면 됩니다. 트레이닝의 예시를 들어봅시다. 임의의 사인파를 들려주고 이 소리가 얼마의 주파수를 가지고 있는지 맞춰볼 것입니다. 사인파의 주파수를 맞춘다는 목적을 가지고 수차례 반복되는 실험에서 정답과 오답을 반복하여 이루어지는 루틴을 통해 뇌에 사인파 소리에 대한 경험이 축적됩니다(=트레이닝). 이 경험이 쌓인 사람과 그렇지 않은 사람이 사인파의 주파수를 맞춘다고 했을 때, 경험이 많은, 즉 트레이닝이 충분히 된 사람이 정답을 더 잘 맞출 것입니다.

그림 1) Perceived sound width training
또 다른 예로 소리의 너비를 트레이닝 할 수 있습니다. 그림 1은 동일 수평면에 스피커 5개를 배치하여 소리의 너비를 훈련하는 실험입니다. 스피커 하나에서만 소리가 나는 것은 가장 너비가 좁은 포인트 음원이 되고, 5개의 스피커에서 모두 소리가 나는 것은 너비가 큰 전방위 음원이 됩니다. 이 트레이닝에서는 소리 나는 스피커 수를 다르게 하는데, 이것은 이 정도의 음원이 얼마 만큼의 너비를 가지는 음원이라는 것을 인지하고 그 경험을 축적하는 과정입니다.
일단 소리를 듣는 환경이 주어지고 그 환경 속에서 듣고자 하는 목적에 맞게 훈련함으로써 청음 능력이 향상 될 수 있습니다. 사실 소리의 주파수나 너비는 일상생활에서 우리에게 중요한 요소는 아닙니다. (소리를 듣고 ‘이 소리의 주파수가 얼마일까?’하고 생각하는 경우는 거의 없겠죠!) 그럼 우리가 트레이닝 해볼 수 있는 보다 중요한 요소에는 무엇이 있을까요?
요즘 VR, AR 등 가상현실에 대한 관심이 매우 높은데요, 가상현실에서 사람의 오감을 충족시키는 데에는 단순히 눈에 보이는 비전(vision) 뿐 아니라 “소리”도 매우 중요한 요인이 됩니다. 특히 가상현실에는 2D 비디오에서 벗어나 3D의 공간적 요소가 가미되기 때문에 소리의 방향에 대한 인지(interaction)가 핵심 요소로 떠오르고 있습니다. 소리의 방향은 사람이 소리를 듣고 그 소리가 나는 방향으로 쳐다 보게 만드는, 즉 소리를 들은 뇌가 그 소리에 대한 사람의 반응을 이끌어내는 매우 중요한 요소입니다. 그럼 여기서 새로운 질문을 던지겠습니다. 사람이 소리의 방향을 인지하는 것도 트레이닝의 결과일까요? 그렇다면 트레이닝이 가능할까요?
사람의 청각 기관의 방향 큐 (Localization Cues of Human Hearing System)
위의 질문의 답을 찾기 위해서 먼저 앞에서 언급했던 ‘중요한 큐’들에 대해 살펴보겠습니다. 귀의 생물학적인 관점이 아니라 소리가 뇌로 전달될때의 우리의 인지적 관점에서 접근해봅시다. 가장 쉽게는 ‘머리 전달 함수(Head Related Transfer Function, HRTF)’를 통해 큐들을 살펴 볼 수 있습니다. HRTF란 어떤 소리의 이벤트가 발생했을 때 그 소리가 발생한 지점부터 우리의 두 귀 까지의 전달 경로를 의미합니다. HRTF를 통해 우리는 다음의 세가지의 큐들을 확인할 수 있습니다.
- Interaural Level Difference (ILD) (두 귀에서의 소리의 크기 차이)
- Interaural Time Difference (ITD) (소리가 두 귀에 전달되기까지의 시간 차이)
- Spectral Cue (주파수 단서)
사람의 두 귀는 머리의 지름 만큼 떨어져 있습니다. 그래서 생기는 큐가 ILD와 ITD죠. ILD는 소리가 두 귀에 도달했을 때의 두 귀에서의 소리의 크기의 차이, ITD는 소리가 두 귀에 전달되기까지의 시간차입니다. spectral cue는 귓바퀴 모양 등으로 생기는 주파수 특성입니다.
이 세가지 큐는 소리가 어느 방향에서 들려오는지 인지하는 데 주된 역할을 합니다. ILD는 수평 방향의 고주파 소리를 인지하는 데 주로 사용되며, ILD는 수평 방향의 저주파 소리를 인지하는 데 주로 사용 됩니다. spectral cue는 ILD나 ITD와는 다르게 수직 방향으로의 소리를 인지하는데 중요한 큐입니다.
우리는 태어나서 지금까지 나의 귀만 가지고 소리를 들어왔는데, 만약 친구의 귀를 내 귀로 사용하게 된다면 어떠한 일이 벌어질까요? 이것에 대한 재미있는 실험이 있습니다.
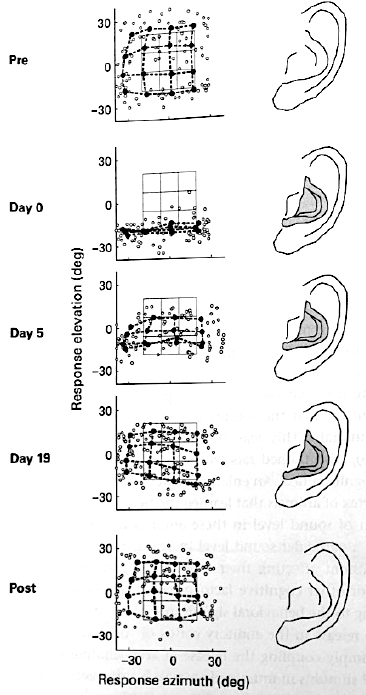
그림 2) Relearning sound localization with new ear
그림 2는 사람의 귓바퀴 모양을 인위적으로 변화시켰을 때 사람이 소리의 방향을 어떻게 인지하는지, 그리고 인지가 시간에 따라 어떻게 변화하는지에 대한 실험 결과 입니다. 그림 2의 3×3 격자는 실제 소리가 발생한 지점이고, 검은 동그라미는 실험자가 소리를 듣고 그것이 어디에서 들려오는지 응답한 것의 평균입니다. (x축은 azimuth(방위각), y축은 elevation(높이))
그림 1의 첫번째 그림은 나의 원래 귀를 가지고 실험한 것입니다. 소리가 발생한 지점을 유사하게 찾아내는 것을 알 수 있습니다(당연한 이야기지만!). 두번째 그림은 인위적으로 귓바퀴를 변화시킨 첫째날의 실험 결과 입니다. 그래프를 보시면 azimuth 축으로 방향을 인지하는 것은 큰 영향을 받지 않았지만 elevation의 변화는 거의 느끼지 못하게 되었음을 알 수 있습니다. 귓바퀴를 변화시켰다는 것은 세 가지의 방향큐 중에 spectral cue가 크게 바뀐 경우에 해당합니다. 실험자의 머리 크기가 바뀌지 않으니 ILD와 ITD는 크게 변화가 없어 azimuth는 원래 귀와 마찬가지로 어느 정도 잘 인지하는 반면, spectral cue는 크게 바뀌어 실험자가 elevation을 인지하는데 문제가 생겼다는 것을 유추할 수 있습니다. 그러나 세번째, 네번째 그림으로부터 우리는 놀라운 사실 하나를 확인할 수 있습니다. 5일이 지나자 바뀐 귀로도 elevation의 변화를 느끼기 시작한 것이 보이고 19일이 지나자 마치 나의 귀로 방향을 인지하는 것처럼 elevation을 느낄 수 있게 된 것입니다. 이는 실험자의 뇌가 변화된 외부 환경으로부터 들어오는 소리를 다시 트레이닝하여 변화된 spectral cue로부터 elevation을 인지할 수 있게 된 것입니다.
그렇다면 다시 원래 나의 귀로 돌아온다면 어떻게 될까요? 바뀐 spectral cue로 새롭게 트레이닝 했으니 원래 귀로 돌아왔을 때 마치 귀가 새롭게 바뀐 것처럼 elevation을 느끼지 못할까요? 신비롭게도 이전에 경험하고 트레이닝된 큐들을 잃어버리지 않고 그대로 유지하는 것을 다섯번째 그림을 통해 알 수 있습니다. 즉 사람의 뇌는 새로운 외부 환경의 변화에도 불구하고 이를 트레이닝 하여 적응 할 수 있을 뿐만 아니라 트레이닝된 경험과 큐를 잃어버리지 않고 유지할 수 있습니다. 이는 사람의 뇌가 훈련을 통해 하나의 HRTF가 아니라 복수의 HRTF를 가질 수 있다는 것을 의미합니다.
AR에서의 방향 인지 훈련 (Auditory Localization Training in AR)
가상 현실에서 소리는 HMD와 더불어 헤드폰을 통해 재생됩니다. 이때 소리의 방향을 정위시키기 위한 방법으로는 HRTF(머리 전달 함수, Head Related Transfer Function)를 사용하는 것이 널리 쓰이고 있습니다. 예를 들어, 소리를 45도 방향에 위치시키고자 하면 방향성이 없는 모노 음원을 45도로부터 측정된 HRTF와 필터링하여 마치 소리가 45도에서 들려오는 것과 같이 만들어 낼 수 있습니다. 일반적으로 HRTF는 KEMAR라고 하는 이어폰/헤드폰 측정용 마네킹을 가지고 획득합니다. 잔향이 없는 무향실에서 소리를 발생시켜, 소리가 발생한 지점부터 마네킹의 두 귀까지 전달되는 경로를 측정하는 것입니다. 이렇게 측정된 HRTF는 사용자의 귀에서 직접 측정하지 않고 마네킹으로 측정한 것이기 때문에, 소리를 듣는 청자의 머리 크기, 귓바퀴 모양, 몸과 같은 사용자의 신체 특성이 반영되어 있지 않습니다. 따라서 이를 ‘비개인화 HRTF’ (non-individual HRTF) 라고 부릅니다. 반대로 사용자의 귀로부터 직접 측정한 것을 ‘개인화 HRTF’ (individual HRTF)라고 합니다.
시중에 나와 있는 VR 혹은 AR 장비들은 대부분 비개인화 HRTF를 사용하고 있습니다. 개인화 HRTF를 측정하는 것은 공간적, 시간적으로 더 큰 비용이 소모되는 일인데다가 각 개인별로 모든 데이터 베이스를 보유하는 것은 불가능에 가깝기 때문입니다. 나와 마네킹은 신체 특성도 다르고 귓바퀴 모양도 달라 모든 방향 큐들이 다릅니다. 즉 내 귀에서 측정된 HRTF가 아니라 마네킹에서 측정된 HRTF를 쓴다는 것은 새로운 귀(마네킹의 귀)를 통해 소리를 듣는 것과 같다고 볼 수 있습니다. 앞서 소개드린 실험에서 훈련을 통한 spectral cue 변화 가능성을 확인한 것처럼, HRTF를 통해 만들어진 새로운 귀도 트레이닝을 통해 마치 나의 HRTF인것처럼 뇌에 탑재 가능하지 않을까요? 그럼 한번 트레이닝을 해 봅시다!


그림 3) Test AR Device 그림 4) Localization Training Software
그림 3은 M사에서 개발된 AR 디바이스입니다.(비개인화 HRTF를 사용한 sound spatializer가 탑재 되어 있습니다.) 그림 4는 AR 디바이스에서 소리의 방향 인지 트레이닝을 할 수 있는 소프트웨어의 화면입니다. 트레이닝은 소리 이벤트가 청취자를 둘러싼 임의의 위치에서 발생하면 청취자는 그 소리의 방향을 찾아 화면을 터치하는 방식으로 이루어집니다. 그러면 소리가 발생한 위치를 청취자에게 정확하게 표시해주고 터치한 지점과 얼마나 맞는지 확인할 수 있는 것이죠. 아래에서 실험 결과를 자세히 살펴보겠습니다.
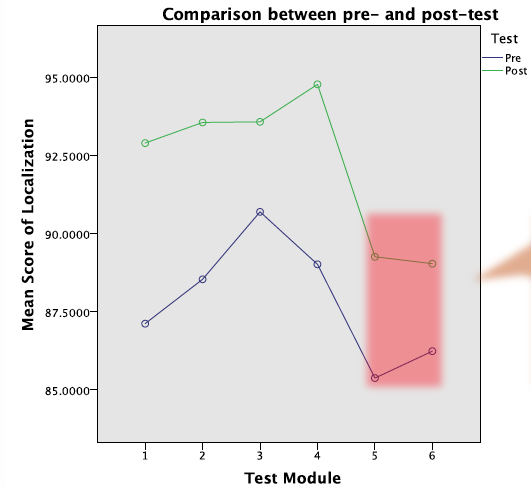
그림 5) 트레이닝 전후 테스트 결과
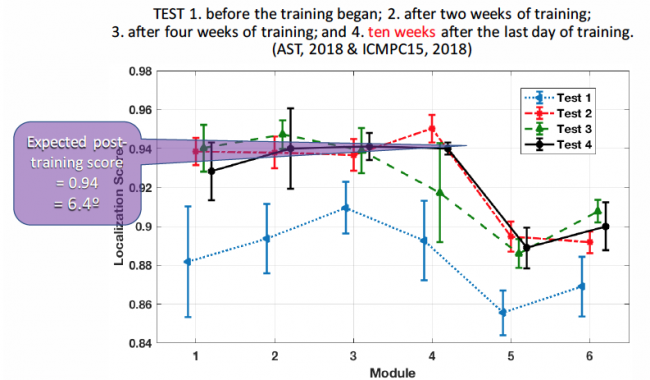
그림 6) 장기 테스트 결과
그림 5는 트레이닝 전과 후의 테스트 결과입니다.(보라 : 트레이닝 전, 초록 : 트레이닝 후) x축은 테스트 모듈이고 y축은 점수입니다. 점수는 정답과 사용자가 터치한 위치와의 차이를 계산한 것으로, 1에 가까울수록 사용자가 정답에 근접했다는 것을 의미합니다. 결과에서 알 수 있듯이 트레이닝 전보다 후에 점수가 더 높게 나타났는데, 이는 피실험자가 비개인화 HRTF에 적응하여 소리 방향에 대한 인지 능력이 트레이닝 후에 더 좋아졌다는 것입니다. 그림 6은 트레이닝 결과가 얼마나 지속되는지에 대한 실험의 결과입니다. 테스트4와 테스트2, 3, 4의 점수가 큰 차이 없다는 점을 통해 10주가 지난 뒤에도 트레이닝의 경험이 사라지지 않고 그대로 유지되는 것을 확인 할 수 있습니다.
이 실험을 통해 트레이닝으로 소리의 청음 능력 향상, 다시 말해 뇌가 새로운 환경에 적응하여 더 정확히 소리 localization을 인지할 수 있도록 relearning하는 과정이 가능하며, 일시적인 것이 아니라 유지된다는 것을 알아보았습니다. 그런데 이런 트레이닝이 무조건 잘 되는 것은 아닙니다. 트레이닝의 효과가 보이지 않는 경우도 발생하는데 여기에는 집중도(attention) 등이 큰 영향을 미칩니다. 10시간 대충 공부하는 것보다 1시간이라도 집중적으로 공부할 때 더 성적이 잘 오르는 것과 같은 이치이죠. 시간이 지날수록 동일한 환경에서 반복적으로 계속되는 트레이닝 과정이 지루해지고 집중도가 떨어질 수 있습니다. 더 나은 트레이닝을 위해 실험자의 관심과 집중도를 유지시키는 것이 중요한데, 소프트웨어를 게임으로 만든다든지 실험자가 좋아하는 음원을 사용한다든지 하는 방법을 고안해 볼 수 있습니다. 그렇지만 가장 중요한 것은 트레이닝의 목적을 달성하고자 하는 실험자의 의지일지도 모르겠습니다.
결론 (Conclusion)
이상으로 localization training에 관련된 재미있는 실험을 통해 귀로 들어오는 소리에 대한 뇌의 반응을 트레이닝으로 향상시킬 수 있다는 사실을 알아보았습니다. 트레이닝 경험이 뇌에 쌓이면 그 경험들이 새로운 환경에 대한 적응력으로 나타나게 됩니다. 이로써 소리의 특징들에 대한 인지 능력이 향상되고, 심지어 우리가 지금까지 써오던 귀를 버리고 새로운 귀를 사용할 때에도 금새 적응할 수 있는 것입니다. 아직은 전국민이 스마트폰을 쓰는 것처럼 AR, VR이 실생활에 깊이 들어와 있지는 않은 상황이라 이에 대한 소리 경험도 충분하지 않습니다. 멀지 않은 미래에 가상 현실에서의 소리 경험이 축적되면 우리는 현실 세계 속의 귀 뿐만 아니라 또 다른 세계에 ‘second ears’를 가지게 될 것 같습니다!

다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
