으라차차! 막내 개발자 Asher의 AI Layer 최적화 구현기
으라차차! 막내 개발자 Asher의 AI Layer 최적화 구현기
(Writer: Asher Kim)
AI가 이렇게나 가까이 우리들의 피부에 닿아있던 적이 있었을까 싶을 정도로 최근 AI의 사용이 점점 더 대중화되고 있습니다. 매일 쏟아져 나오는 뉴스만 봐도 알 수 있죠. 지난 포스팅(소리 만들어주는 AI는 없나요? : 사운드와 생성 AI)을 통해 소개해드렸듯, 가우디오랩에서도 여러 AI 제품들을 준비하고 있는데요! 저는 이번 글을 통해 가우디오랩이 AI 오디오 제품을 연산 측면에서 어떻게 최적화해나갔는지, 그 좌충우돌 과정을 간단히 소개해드리려고 합니다.
오디오에 AI 적용하기
AI는 사람이 직접 알고리즘을 작성하기 어려운 문제를 쉽게 해결해 줍니다. 소리를 듣고 악기 별로 음원을 분리하거나, 주어진 키워드에 맞는 소리를 생성하는 건, 아무래도 그 과정을 표현하기 쉽지 않아보이는데요. 가우디오랩의 AI 제품들은 이러한 어려운 문제들을 데이터에 기반해 자동으로 학습하고 패턴을 파악하여 해결합니다. 그럼 본격적인 내용에 들어가기에 앞서서, 가우디오랩의 AI가 얼마나 잘 문제들을 해결했는지, 한 번 확인해 볼까요? ▶︎▶︎▶︎ [데모 먼저 확인하고 오기]
성능은 중요합니다
가우디오랩의 오디오 제품은 크게 온라인 방식과 오프라인 방식으로 나눌 수 있습니다. 온라인은 서버에서 연산해서 사용자에게 보내는 방식이고, 오프라인은 사용자의 컴퓨터나 핸드폰, 이어폰 등에서 연산하는 방식입니다. 후자는 엣지 컴퓨팅이라고도 합니다.
온라인 방식은 주로 큰 모델을 제품화할 때 사용됩니다. 그렇기 때문에 더 저렴하면서도 안정적인 서비스를 제공하기 위해서는 최적화를 통해 서버 비용을 낮추고 수행 시간을 줄이는 것이 중요합니다. 한편, 오프라인 방식은 주로 작은 모델을 제품화할 때 사용되는데, 특히 실시간 처리가 요구되는 경우가 많습니다. 디바이스에서 수행중인 다른 작업들을 최대한 방해하지 않으면서 실시간 처리가 가능하게 하기 위해서는, 역시나 최적화를 통해 연산량 및 수행 시간을 줄여야 합니다.
결론적으로, 최적화 과정은 오디오 제품을 만들 때, 특히 AI를 사용하는 데 있어 필수적인 부분입니다. 아래에서는 가우디오랩이 세계 최고 수준의 성능을 자랑하는 AI 오디오 제품을 개발한 과정을 소개합니다.
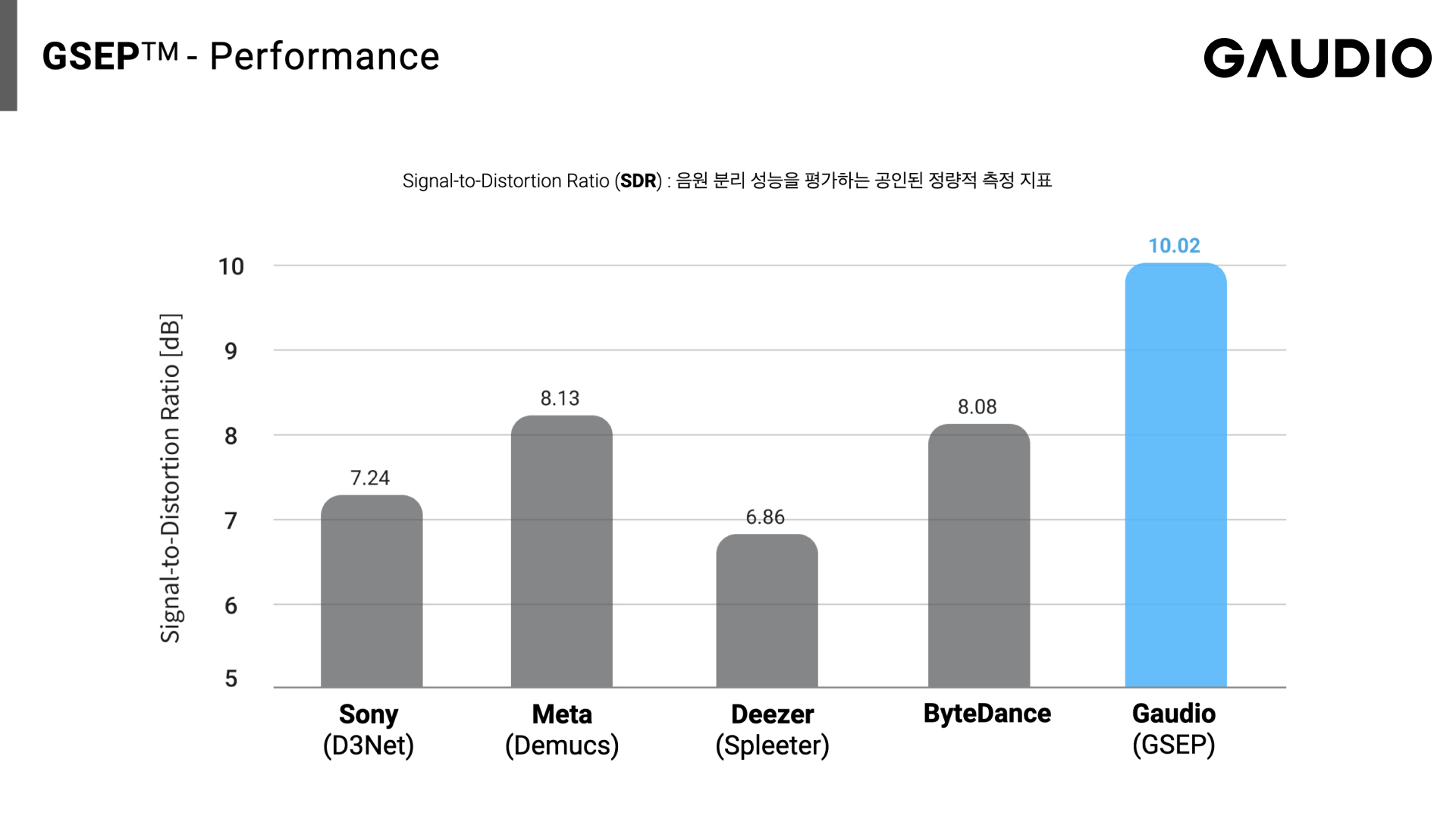
세계 최고 성능을 자랑하는 가우디오랩의 AI 음원분리 기술!
항상 최적화가 필요한 것은 아닙니다
그러나 모든 단계에서 최적화가 중요한 것은 아닙니다. 최적화를 마쳤는데 모델이 수정될 수도 있고, 들인 시간에 비해 이득이 별로 없을 수도 있습니다. 그리고 이른 단계에서부터 최적화를 생각하다가는, 자칫 중요한 로직에 집중하지 못하게 될 수도 있죠. 그러므로 팀 (또는 회사) 내에서 최적화에 대한 합의가 이루어지는 것이 중요합니다. 언제, 얼마나 시간을 쓸지, 어떤 최적화를 수행할지 등에 대해서요.
가우디오랩은 비전에 대한 동기화만 이루어져 있다면 누구나 주도적으로 업무를 만들어서 수행할 수 있는 회사이기 때문에, 저는 최고의 제품을 만들기 위해서는 최적화가 필수적임을 팀 내에 설득했고, 모델 개발이 완료될때 쯤부터 연산 최적화 업무를 시작할 수 있게 되었습니다. 최고의 효율을 내기 위해 생각과 일정을 공유하고 협의하며 결정된 순간이었죠.
최적화를 해봅시다
AI 제품의 최적화는 크게 모델 경량화와 연산 최적화로 나눌 수 있습니다. 모델 경량화는 원본과 의미는 비슷하지만 연산의 수는 적은 모델로 갈음하는 것이고, 연산 최적화는 동일한 연산을 더 빠르게 수행하는 것입니다. 이 글에서는 GSEP-LD의 연산 최적화를 위해 저와 저희 팀이 한 삽질노력들을 설명해 보겠습니다.
측정하세요!
본격적으로 최적화를 논하기 전에, 측정의 중요성은 아무리 강조해도 모자라지 않습니다. 암달의 법칙에 따라 우리는 가장 많은 시간 비중을 차지하는 코드부터 최적화해야 합니다. 그런데 성능에는 아주 다양한 요소가 영향을 주기 때문에, 성능을 예측하는 것은 커녕, 올바르게 성능을 측정하는 것조차 무척 어렵습니다. 이에 대해서는 아래의 두 영상에 잘 설명되어 있습니다.
· CppCon 2015: Chandler Carruth "Tuning C++: Benchmarks, and CPUs, and Compilers! Oh My!"
· CppCon 2015: Bryce Adelstein-Lelbach "Benchmarking C++ Code"
나아가 측정 결과를 잘 해석하는 것도 중요합니다. 평균과 중앙값을 통해 전체적인 추이를 알 수 있고, 다른 코드와 비교할 때는 Student's t-test 등의 방법을 사용해 유의미한 차이가 나고 있는지 검증할 수 있습니다. 또한 실시간 오디오 처리라면 하위 1%의 성능도 중요하게 봐야 합니다. 잠깐이라도 실시간을 맞추지 못한다면 바로 소리가 끊기기 때문입니다.
다른 프레임워크 사용하기
PyTorch는 머신러닝 모델의 연구 과정에서 주로 사용하는 프레임워크입니다. 사용이 편리하다는 장점이 있지만, 경우에 따라 Inference 성능이 다른 프레임워크에 비해 부족할 수 있습니다. GSEP-LD PyTorch 버전은 RTF 0.65 수준이었는데, 이 정도면 다른 프로그램이 동시에 실행중이거나 성능이 좋지 않은 프로세서를 사용하는 경우엔 실시간을 맞추기 어려우므로, 저희는 다른 프레임워크들을 검토했습니다.
CoreML은 Apple 기기에 머신러닝 모델을 서빙하기 위한 프레임워크입니다. Apple 기기의 하드웨어 자원을 적극적으로 활용할 수 있고, 쉽게 프로파일링할 수 있다는 장점이 있습니다. 기본적으로는 coremltools를 사용해 PyTorch 모델을 CoreML 모델로 변환하고, CoreML에서 기본적으로 지원하지 않는 레이어는 MLCustomLayer를 통해 수동으로 작성할 수 있습니다.
TFLite (TensorFlow Lite) 는 모바일 기기 등에 머신러닝 모델을 서빙하기 위한 프레임워크입니다. PyTorch 모델을 TFLite 모델로 바꾸는 데는 다음의 두 방법이 있습니다.
· TensorFlow 2.0 부터는 PyTorch와 거의 비슷한 코드로 모델을 만들 수 있으므로 직접 재작성
· Torch 모델 → ONNX 모델, ONNX 모델 간소화, ONNX 모델 → OpenVINO 모델, OpenVINO 모델 → TFLite 모델의 과정을 거쳐 자동으로 변환
첫 번째 방법의 경우 많은 작업이 필요하지만 가장 확실하게 모델을 포팅할 수 있다는 강점이 있습니다. 두 번째 방법의 경우 시간은 적게 걸리지만 각각의 변환 방법들이 모든 레이어를 지원하는 것은 아니기 때문에, 몇몇 레이어는 수동으로 구현해줘야 합니다. 그 중 저는 두 번째 방법을 통해 원본 PyTorch 모델을 TFLite 모델로 변환했고, GRU 레이어를 수동으로 구현하는 어려움이 있었지만, Apple M1 및 2스레드에서 RTF 0.06 수준을 달성했습니다.
안된다면? 직접 프레임워크 구현하기!
하지만 가우디오랩에서는 이 프레임워크들을 사용할 수 없었습니다. 더 높은 성능이 필요했고, SDK 제품 측면에서는 타 라이브러리에 디펜던시가 없는 것이 유리했기 때문입니다. 그래서 저희는 직접 머신러닝 프레임워크를 개발하기로 했습니다. 이 글에서는 머신러닝 프레임워크를 구현하며 각 레이어를 최적화하기 위해 사용한 기법들 중 몇 가지를 소개하려고 합니다.
메모리에 순차적으로 접근하기
Inference Engine에서 가장 중요한 부분 중 하나는 각 레이어의 성능을 높이는 것입니다. 제가 받은 모델은 이미 상당히 경량화되어 있어서, 캐시를 적극적으로 활용할 수 있도록 하는 것이 가장 중요했습니다.
우선 메모리에 순차적으로 접근하도록 하는 것부터 시작해 봅시다. 예를 들어 메모리에 3 x 3 텐서의 각 원소는 다음과 같은 형태로 저장되어 있을 것입니다.
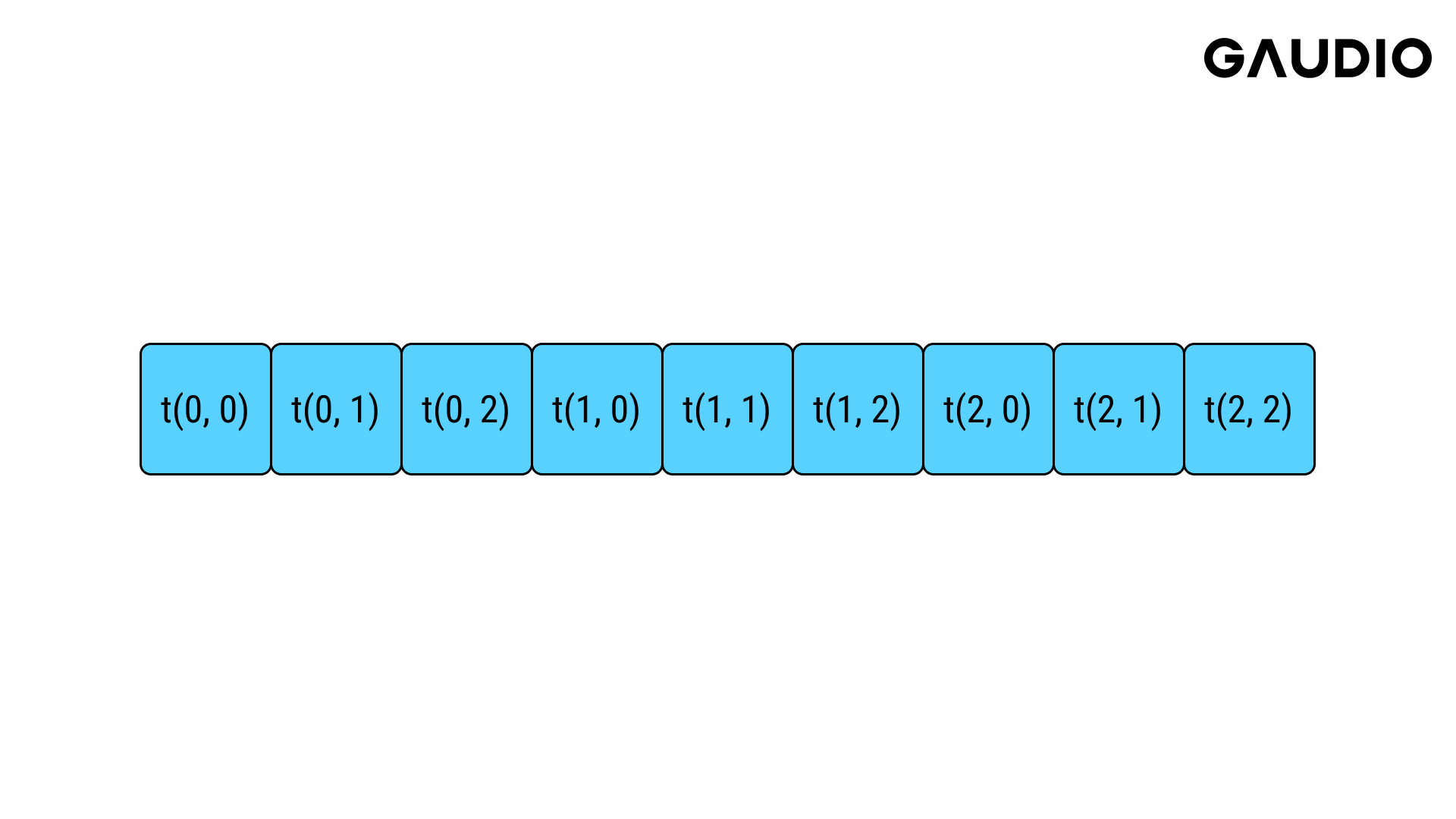
그리고 이 원소들의 합을 구하는 코드는 다음과 같이 작성할 수 있습니다.

이 코드가 메모리에 접근하는 순서는 다음과 같을 것입니다.
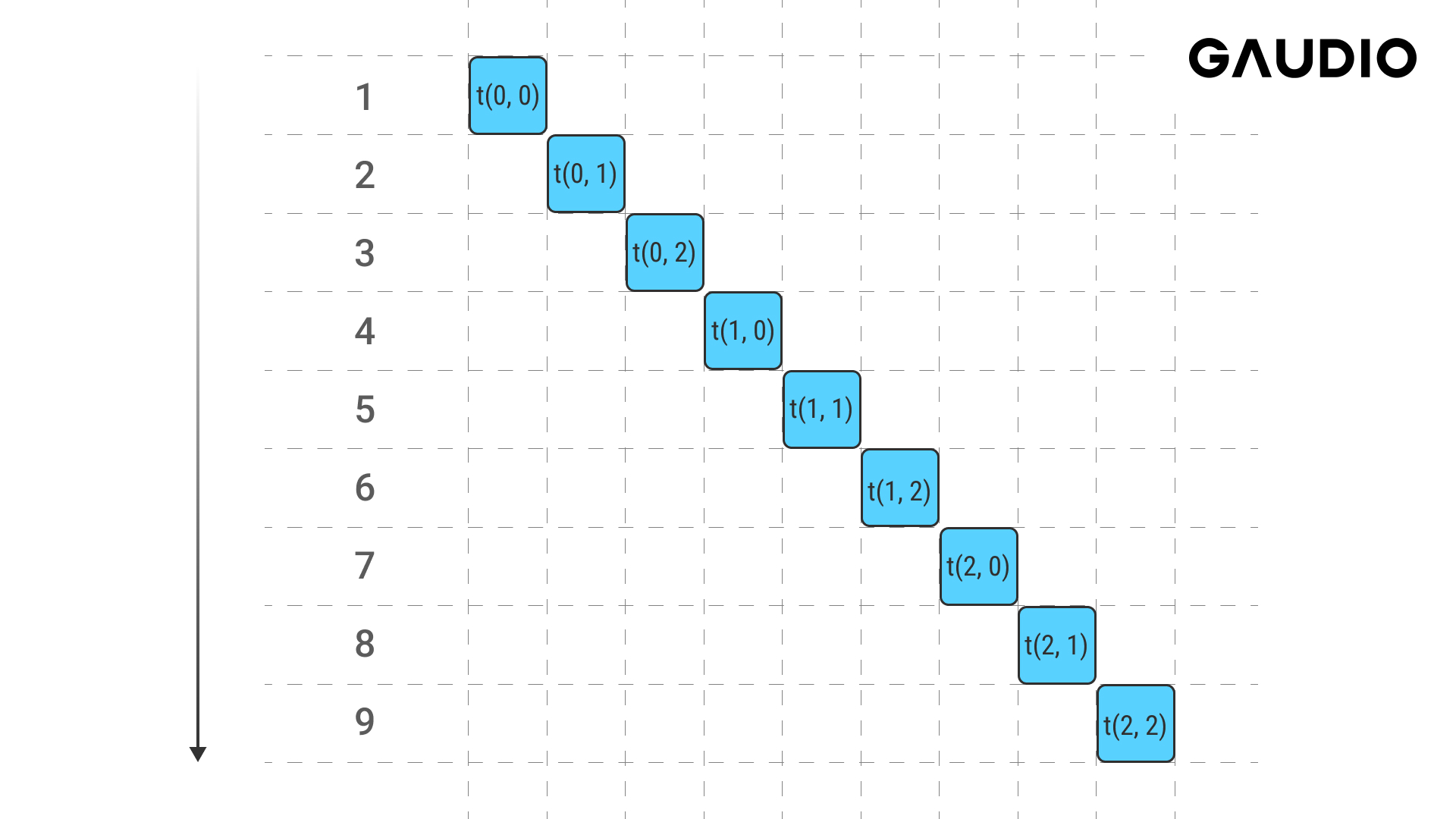
같은 기능을 하는 코드를 이렇게도 작성할 수 있습니다.

그리고 이 코드가 메모리에 접근하는 순서는 다음과 같을 것입니다.
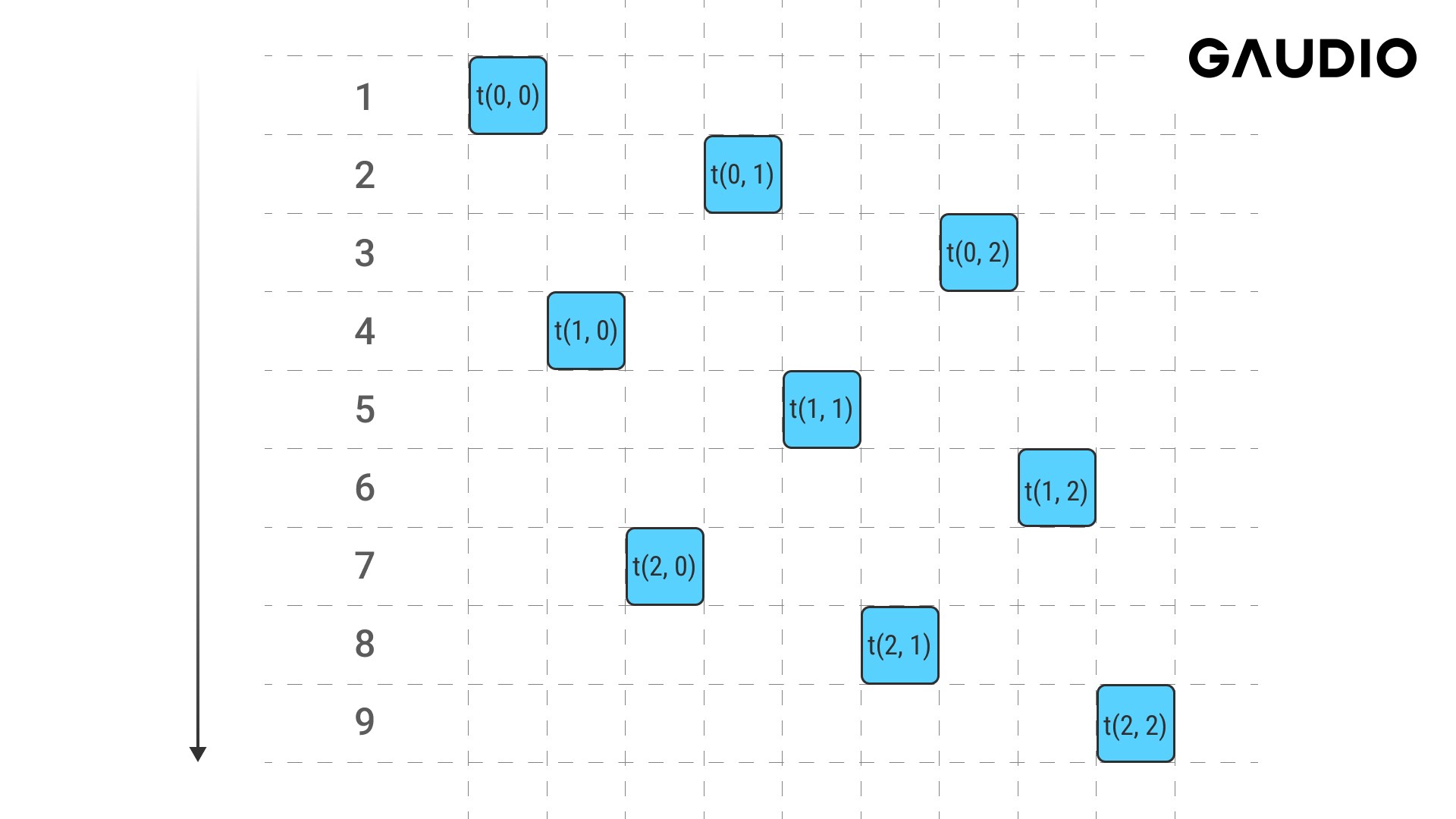
첫 번째 코드는 메모리에 순차적으로 접근합니다. 캐시는 인접한 메모리를 한 번에 읽어오므로, 첫 번째 코드는 캐시 적중률이 높을 것입니다. 반면 두 번째 코드는 메모리에 띄엄띄엄 접근합니다. 텐서의 크기가 작을 때는 별로 차이가 나지 않을지 몰라도, 텐서의 크기가 커지게 되면 메모리에 접근할 때마다 캐시에 다시 적재해야 하므로 성능이 하락합니다. 추가로, 메모리에 순차적으로 접근하는 코드는 컴파일러가 자동 벡터화를 수행해줄 확률이 높습니다. 따라서 두 번째 코드처럼 메모리에 순차적으로 접근하지 않는 코드는 최소화하는 것이 좋습니다.
메모리 쪼개기
하지만 메모리에 순차적으로 접근한다고 해도, 이것이 반복되면 매번 캐시에 새로 적재해야 합니다.

t2는 j와 k를 통해 메모리에 순차적으로 접근하지만, 가장 바깥의 i 때문에 캐시 활용성은 좋지 않아 보입니다. 이를 해결하기 위해서는, t2를 줄대로 쪼개서 for문 순서를 바꾸는 것이 좋아보이네요.

위의 두 기법은 머신러닝에서 가장 많이 사용되는 레이어인 Conv2D과 Linear 등에도 적용할 수 있습니다.
데이터 병렬
의존성이 없는 작업이라면 데이터 병렬을 도입하는 것도 좋습니다. OpenMP를 사용하면 데이터 병렬을 손쉽게 적용할 수 있습니다.

다만, 성능이 병렬화에 크게 의존하면 같이 실행되고 있는 프로그램이나 하드웨어 등 주변 상황에 영향을 많이 받게 되므로, 병렬화는 최대 성능을 높이는 데에 의의를 두는 것이 좋겠습니다. 또한, False Sharing 등의 문제가 발생할 수 있어 메모리 측면에서의 최적화가 까다로워지니, 벤치마킹을 통해 적용 여부를 결정하는 것이 좋습니다.
루프 언롤링
루프를 사용하게 되면 중단 조건에 대한 오버헤드가 발생합니다. 이는 아무리 분기 예측과 파이프라이닝이 발전해도 어쩔수 없죠. 하지만 여러 번의 번의 루프를 한 묶음으로 처리해서 뜨문뜨문 중단 조건을 검사한다면, 이러한 비용을 아낄 수 있을 것입니다. 상황에 따라 다르지만, 경험상 4번의 루프를 한 묶음으로 처리할 때가 가장 성능 향상 폭이 큰 것 같습니다. 다만 요즘은 컴파일러가 자동으로 언롤링을 수행하는 경우도 있으니, 꼭 컴파일된 결과물을 확인해 보고 사용하세요.

SIMD
일반적으로 CPU 명령어 하나는 데이터 한 개를 처리합니다. SIMD는 명령어 하나로 데이터 여러 개를 처리해, 성능을 향상시키는 기법입니다. C++에서 SIMD를 사용하기 위해서는 인트린직 함수 또는 이를 잘 래핑한 라이브러리를 사용하게 되는데요, 여기서는 xsimd 라이브러리를 사용한 예시를 보여드리겠습니다.

이 코드에 xsimd 라이브러리를 적용하면,

물론 요즘 컴파일러는 똑똑하기 때문에, 많은 케이스에 자동으로 SIMD 명령어를 적용해 줍니다. 그러나 사람만큼 잘 적용하지는 못하기 때문에, 일단 컴파일러가 잘 auto-vectorize할 수 있도록 코드를 작성하고, 컴파일러가 vectorize하지 못하는 부분만 인트린직 함수나 라이브러리를 사용하면 좋습니다. clang의 경우, -Rpass, -Rpass-missed, -Rpass-analysis 등의 옵션을 통해 컴파일러가 적용한 최적화에 대한 레포트를 만들 수 있습니다.
마치며
좋은 제품이라면, 수행 결과뿐만 아니라 수행 성능도 좋아야 합니다. 이번 글에서는 왜 최적화가 필요한지, 가우디오랩에서는 어떠한 과정을 거쳐서 최적화가 이루어지고 있는지를 간단히 설명해드려보았습니다. 앞으로도 저는 세상의 모든 소리를 담은 제품을 만들 수 있도록 더욱 열심히 노력하려고요! 읽어주셔서 감사합니다! 😘


세계적인 음향 기술을 보유한 가우디오랩에 지원해 보세요.
