소리 만들어주는 AI는 없나요? : 사운드와 생성 AI
ChatGPT가 불러온 생성 AI 돌풍
(Writer: Keunwoo Choi)
ChatGPT 만큼 사람들의 삶에 빠르게 스며든 기술이 또 있었을까 싶을 정도로 생성 AI에 대한 관심이 뜨겁습니다. 마치 스마트폰의 초창기를 보는 듯, 새로운 패러다임이 찾아오는 것이 아닐까 하는 기대까지 하게 됩니다. 이처럼 ChatGPT에서 시작된 생성 AI 열풍이 글쓰기가 아닌 미술, 음악과 같은 다른 콘텐츠 영역까지 그 영향력을 확장하고 있음을 실감합니다.
사운드 분야의 생성 AI
사운드 분야도 예외는 아닌데요, 목소리를 AI로 합성하거나 음악을 작곡하는 등의 기술은 이미 많은 관심을 받아왔습니다. 하지만, 우리 주변에서 들려오는 소리를 생각해보면 음성이나 음악의 비중은 사실 크지 않습니다. 오히려 키보드 치는 소리, 옆 사람의 숨소리, 냉장고 소음과 같이 작은 소리가 모여 우리를 둘러싼 소리 환경을 만들고 있습니다. 결국 이러한 소리들이 없으면 아무리 잘 생성된 음성과 음악이라도 충분히 그 빛을 발할 수 없다는 것이기도 합니다.
이렇게 중요하다면, 그동안 우리 주변의 소리(원활한 표현을 위해 ‘효과음(Foley Sound)’이라고 칭하겠습니다)를 만드는 AI가 없었던 이유는 무엇일까요? 답은 간단합니다. 이것이 가장 난이도 높은 일이기 때문입니다. 세상의 모든 소리를 만들기 위해서는 세상의 모든 소리에 대응하는 소리의 데이터를 갖추고 있어야 합니다. 그만큼 고려해야하는 변수도 많을 수 밖에 없습니다.
하지만 이런 어려움에 굴복할 가우디오랩이 아닙니다. 세상의 모든 소리를 만들기 위해서는 세상의 모든 소리에 대응하는 소리의 데이터를 갖추고 있어야 합니다. 그만큼 고려해야하는 변수도 많을 수 밖에 없습니다.
긴 말 할 것 없이 데모부터 들어보시죠.
AI가 만든 소리 VS 실제 소리
여러분은 몇 개의 정답을 맞추셨나요?
들으신 것 처럼 AI가 생성한 사운드의 수준은 실제 녹음된 사운드에 버금갈 정도로 많은 발전을 이루었습니다.
이젠 본격적으로 이렇게 놀랄 정도로 사실적인 사운드를 만들기 위한 AI 기술의 원리를 더 자세히 들여다 보겠습니다.
소리를 AI로 만듭니다.
소리를 표현하는 방식: 파형 그래프
뜬금없어 보이지만 AI로 소리를 만들어내는 과정을 설명하기 위해서는 소리를 표현하는 방식부터 짚고 넘어가야 합니다. 이런 이미지는 아마 많이 보셨을 것 같습니다.
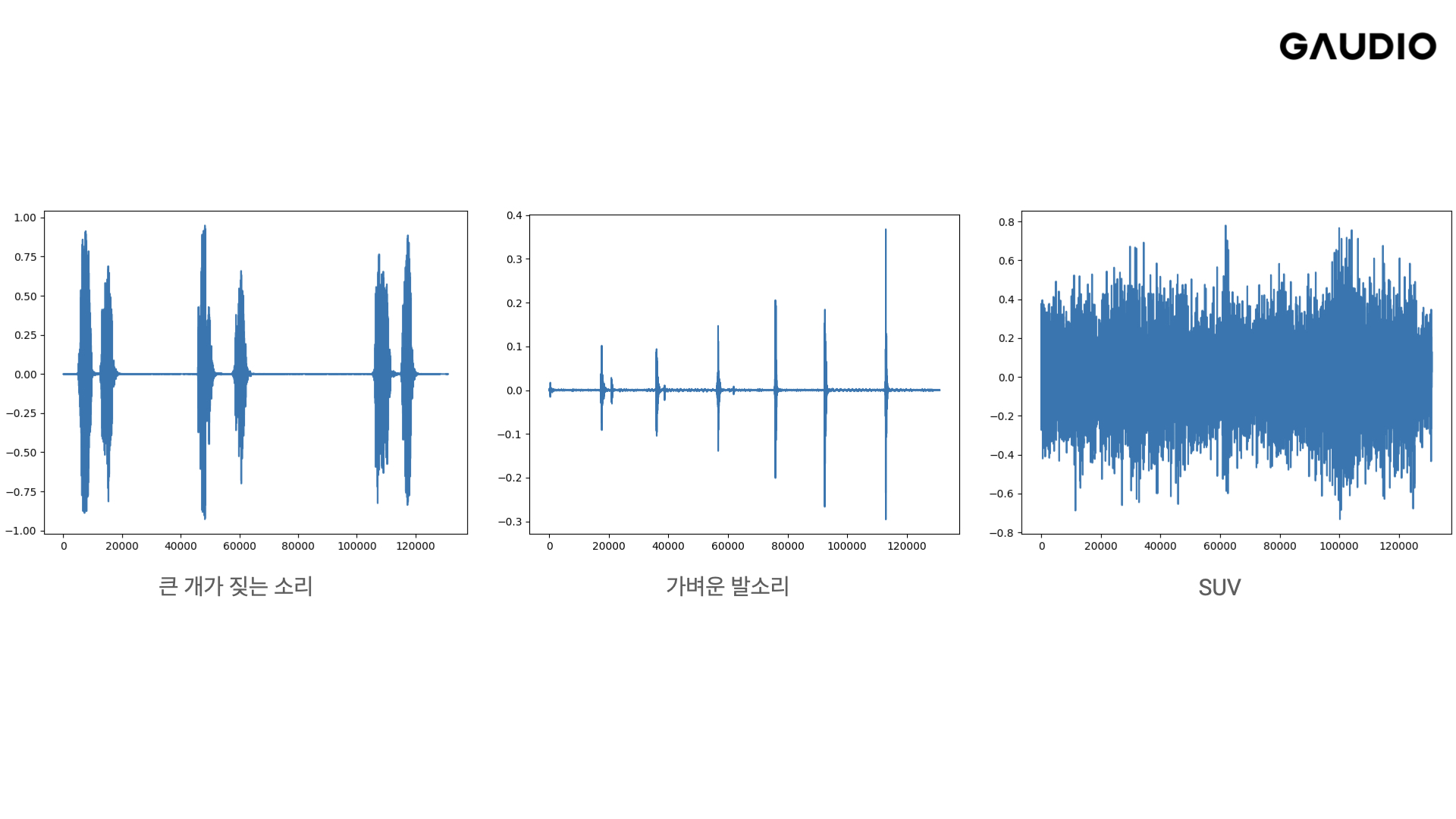
소리의 파형을 시간대별로 나타낸 그래프로, 언제 어느 정도 크기의 소리가 나는지는 짐작할 수 있지만 이 소리가 어떤 특성을 가졌는지까지 파악할 수는 없습니다.
소리를 표현하는 방식: 스펙트로그램 (Spectrogram)
이러한 한계를 극복하고자 만들어진 것이 스펙트로그램입니다.
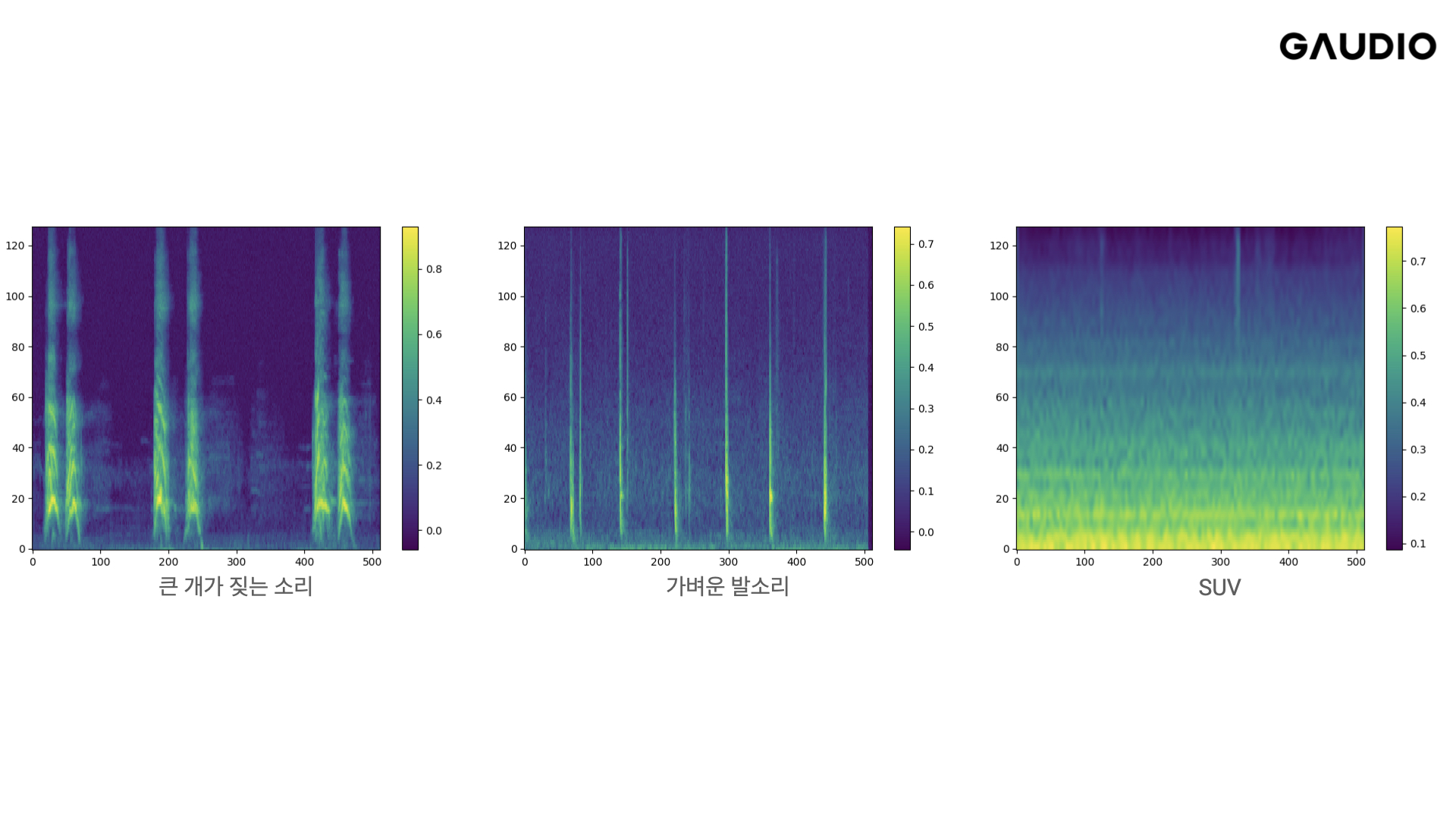
한눈에 봐도 앞선 그래프보다 많은 정보를 담고 있는 것처럼 보입니다.
자세히 살펴보면, x축은 시간, y축은 주파수, 그리고 각 픽셀의 색깔은 소리의 크기를 나타냅니다. 즉, 스펙트로그램은 어떤 소리에 대한 모든 정보를 담고 있는, 마치 소리의 DNA와 같은 존재라고 할 수 있습니다. 그렇기에 스펙트로그램을 오디오 신호로 변환할 수 있는 도구만 있다면, 소리를 만드는 것은 곧 이미지를 만드는 작업과 동일하다고 볼 수 있는것이죠. 이렇게 되면 많은 일이 간단해집니다. Open AI의 DALL-E 2 에서 사용된 것과 같은 디퓨전 기반 이미지 생성 알고리즘을 그대로 사용할 수 있기 때문입니다.
자, 이제 스펙트로그램을 설명한 이유를 아시겠나요? 이젠 정말로 소리를 만드는 과정을 자세히 살펴보겠습니다.
AI로 소리 만들기, 이렇게 합니다.

1단계: 텍스트 입력에서 작은 스펙트로그램 생성하기
첫 단계에서는 만들고 싶은 소리에 대한 입력을 처리합니다. ‘우렁찬 호랑이의 포효’라는 텍스트를 입력으로 받으면, 디퓨전 모델이 랜덤한 노이즈에서 작은 사이즈의 스펙트로그램을 만들어냅니다.
이 때 만들어진 스펙트로그램은 16x64 픽셀로 이루어진 작은 이미지인데요, 각 숫자는 16개의 주파수 밴드와 64개의 프레임을 나타냅니다. 얼핏 보면 이걸로 뭘 할 수 있겠냐는 의문이 드시겠지만 작은 스펙트로그램도 소리에 대한 상당한 정보를 담고 있습니다.
2단계: 슈퍼 레졸루션(Super Resolution)
그 이후에는 이런 작은 이미지를 점차 개선해 나가는 ‘슈퍼 레졸루션’ 단계를 거칩니다. 디퓨전 모델이 여러 단계를 거쳐 해상도를 개선하면 위에서 본 것과 같은 명료한 형태의 스펙트로그램이 완성됩니다.
3단계: 보코더 (Vocoder)
이제 마지막 단계로 스펙트로그램을 오디오 신호로 변환해주기만 하면 됩니다. 이 때 사용되는 것이 보코더 입니다. 하지만 시중에 오픈소스로 공개되어있는 대부분의 보코더는 음성 신호를 학습하여 제작되었기 때문에 다양한 소리에 대응해야 하는 지금과 같은 시나리오에 적합하지 않다는 점이 문제였습니다. 이에 가우디오랩은 내부 데이터로 학습시킨 세계 최고 수준의 보코더를 개발했습니다. 2023년 상반기 중에는 이러한 보코더를 오픈 소스로 공개할 계획도 가지고 있습니다.
사운드 생성 AI, 가우디오랩이 잘 만들 수 밖에 없는 이유
사운드 생성 AI 개발, 왜 어려울까요?
얼핏 보면 쉬워보이는 과정이지만, 마침내 그럴듯한 소리가 나오기까지 정말 많은 장애물을 거쳐야 했습니다. AI는 도구일 뿐, 실제로는 ‘오디오를 잘 해야만’ 풀 수 있는 문제이기 때문입니다.
일단 오디오 데이터는 그 크기가 남다릅니다. ChatGPT가 학습한 데이터는 약 570GB, 지난 10년간 딥러닝 발전을 이끌어온 이미지넷이 다루는 데이터는 약 1,000개의 카테고리에서 150GB 정도입니다. 하지만, 가우디오랩이 다뤄야 했던 데이터는 약 10TB에 달합니다. 이를 시간으로 바꿔보면 약 1만 시간 분량의 데이터입니다. 이것들을 수집하고 관리하는 데만 해도 상당한 노하우가 필요했을 뿐만 아니라, 학습을 위해 오디오 데이터를 불러오는 시간(i/o 오버헤드)를 줄이는 것도 큰 과제였습니다.
어렵게 학습을 시키더라도 오디오의 경우 AI 모델을 평가하는 것 자체가 어렵습니다. 생성된 시간만큼 들어봐야 하기 때문에 평가에 필요한 시간이 클 뿐더러, 청취 환경에도 큰 영향을 받기 때문입니다.
사운드 생성 AI도 전문가가 만들면 다릅니다.
다행히 가우디오랩에는 프라운호퍼, 삼성전자, 스포티파이 등 글로벌 레벨의 기업에서 풍부한 오디오 연구 경험을 쌓은 음향공학 분야의 석박사급 전문가들이 존재하고, 그들이 직접 청취 평가에 참여하고 있습니다. 그렇기 때문에 그들의 소위 ‘골든 이어’ 로서의 예민함, 좋은 소리에 대한 집착, 그리고 뛰어난 전문성이 그대로 AI 성능에도 반영되고, 이것이 세계 최고 수준의 생성 AI를 만들 수 있는 가우디오랩만의 따라올 수 없는 강점이 되고 있습니다.
사운드 생성 AI, 이렇게 발전합니다
가우디오랩이 그리는 미래는 메타버스에 있습니다. 사운드 생성 AI를 만들게 된 것도 소리 없는 메타버스에 소리를 채우기 위함이었습니다. 물론 지금까지 만들어진 모델의 성능이 뛰어나지만, 세상의 모든 소리를 담으려면 가야할 길이 꽤 많이 남았습니다.
DCASE 2023 이벤트 참여 소식
그래서 가우디오랩은 이렇게 어려운 문제를 해결하기 위해 DCASE 라는 이벤트에 Lead Organizer로 참여합니다! 세계 곳곳에서 모인 최고 수준의 오디오 연구자들과 함께 더 좋은 소리를 만드는 여정을 응원하고, 또 가우디오랩이 만들어낸 사운드가 얼마나 좋은지를 널리 알리기 위한 목적입니다.
DCASE의 결과는 5월에 발표됩니다. 과연 이렇게나 뛰어난 가우디오랩의 사운드 생성 AI가 세계에서는 어떤 평가를 받게 될까요? 좋은 소식으로 여러분을 찾아뵐 수 있도록 많은 응원 부탁드립니다!
곧 AI로 만든 소리도 함께 공개할 예정이니 많은 관심 부탁드려요!


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
