공간음향의 퀄리티를 높여주는 Motion-to-sound 레이턴시 측정
공간음향의 퀄리티를 높여주는 Motion-to-sound 레이턴시 측정(Motion to Sound Latency Measurement)
(Writer: James Seo)
[Introduction: 들어가며]
Spatial Audio(공간 음향)는 사용자가 헤드폰이나 이어폰을 통해 듣는 소리를 사용자의 위치와 방향에 맞게 재현하여, 소리가 실제와 똑같은 듯 자연스러운 착각을 주는 오디오 렌더링 기술입니다. Spatial Audio의 품질과 성능에는 공간과 방향의 특성을 렌더링하는 음질 뿐만 아니라 사용자의 움직임으로부터 렌더링되어 소리가 재생되는 데에 소요되는 시간(motion-to-sound latency) 역시 큰 영향을 끼치게 됩니다.
-Motion-to-sound latency가 너무 길게 되면, 시각을 비롯한 현실의 자극체계와 청각 경험의 불일치로 인해 사용자는 몰입감을 잃게 될 뿐만 아니라 심한 경우 멀미가 발생하기도 합니다. 이것은 VR 기기를 사용하였을 때, 시각에서 발생하는 멀미 현상의 원인인, motion-to-photon latency와 동일한 개념입니다.
Spatial audio에 대한 고객 경험을 평가하는 데에는 이러한 motion-to-sound latency의 측정이 필수적인데, 이 측정은 단순한 작업은 아닙니다. 전체적인 motion-to-sound latency는 Figure 1과 같이 나누어서 생각해 볼 수 있습니다. (1) 사용자의 motion을 인지하는 motion-to-sensor latency, (2) sensor가 인지한 움직임이 오디오 프로세서로 전달되는 sensor-to-processor latency, (3) processor에서 rendering 과정에서 발생되는rendering latency, (4) rendering 된 신호가 Bluetooth 등의 통신 경로를 통해 전달되는 과정에서 발생하는 communication latency등이 있는데, 이를 독립적으로 측정하는 것은 쉽지 않고, 특히 시중에 판매되고 있는 완제품의 경우 내부 모듈을 Breakdown하여 측정하는 것은 불가능하다는 문제점이 있습니다.
이 글에서는 motion-to-sound latency를 좀 더 정확하게 측정하기 위한 방법을 설명합니다. 어렵지 않은 내용이니 천천히 따라오시면 잘 이해하실 수 있으리라 생각합니다.
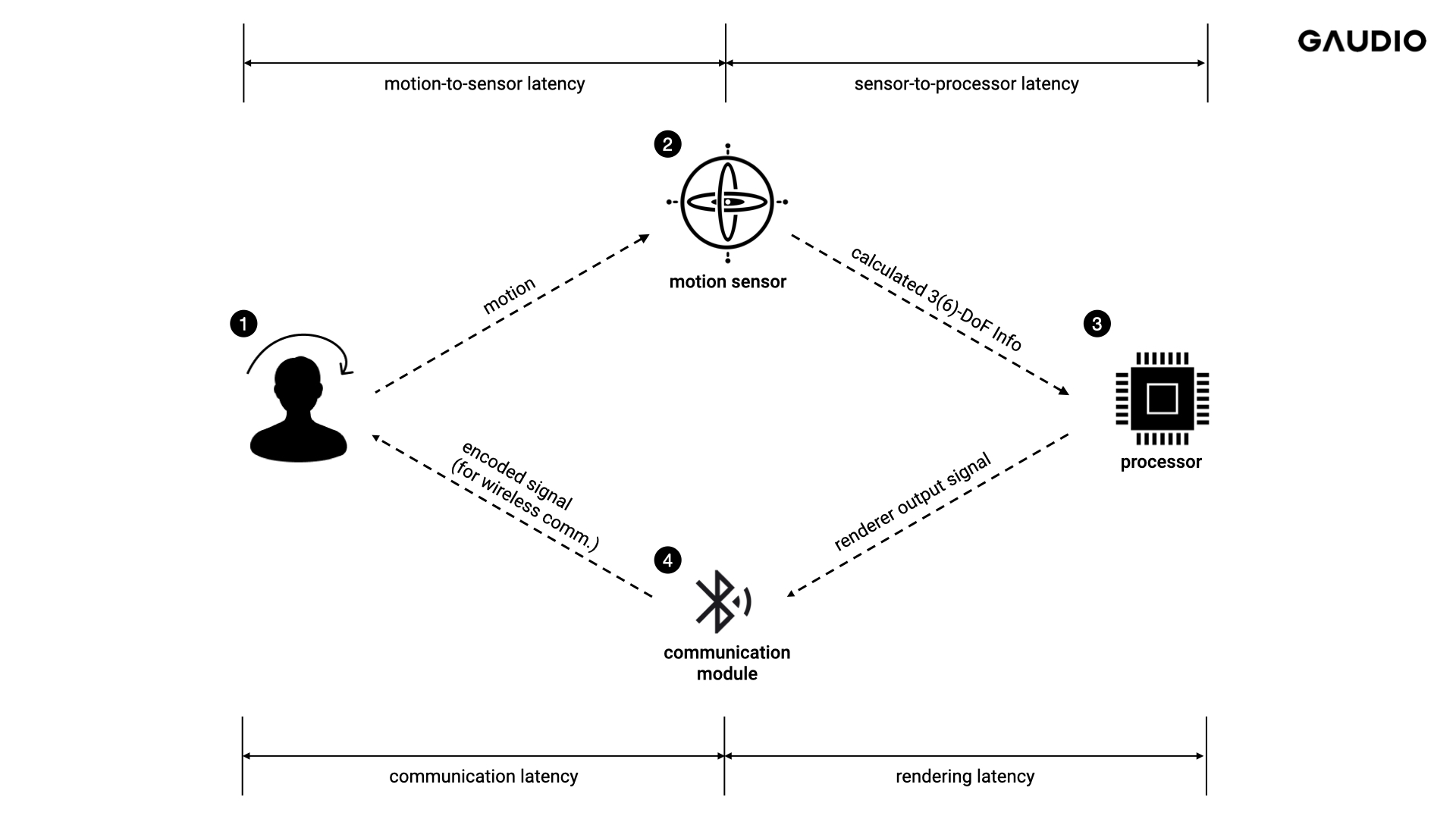
Figure 1 Breakdown of Motion-to-Sound Latency
[Measurement Hypothesis: Binaural Rendering & Crosstalk Cancellation]
앞서 말씀드린 것과 같이 Spatial Audio 는 어떤 공간안에 존재하는 음원을 해당 음원과 청취자의 상대적인 위치에 맞게 렌더링 하는 Binaural Rendering 기술을 활용하고 있습니다. 즉, 음원의 위치 뿐만 아니라 음원이 존재하고 있는 공간의 느낌까지도 함께 재현하기 위한 기술이죠.
일반적으로 Binaural Rendering 을 수행하기 위해서는 BRIRs(Binaural Room Impulse Responses), HRIRs(Head-Related Impulse Responses)과 같은 Binaural Filter를 사용합니다.
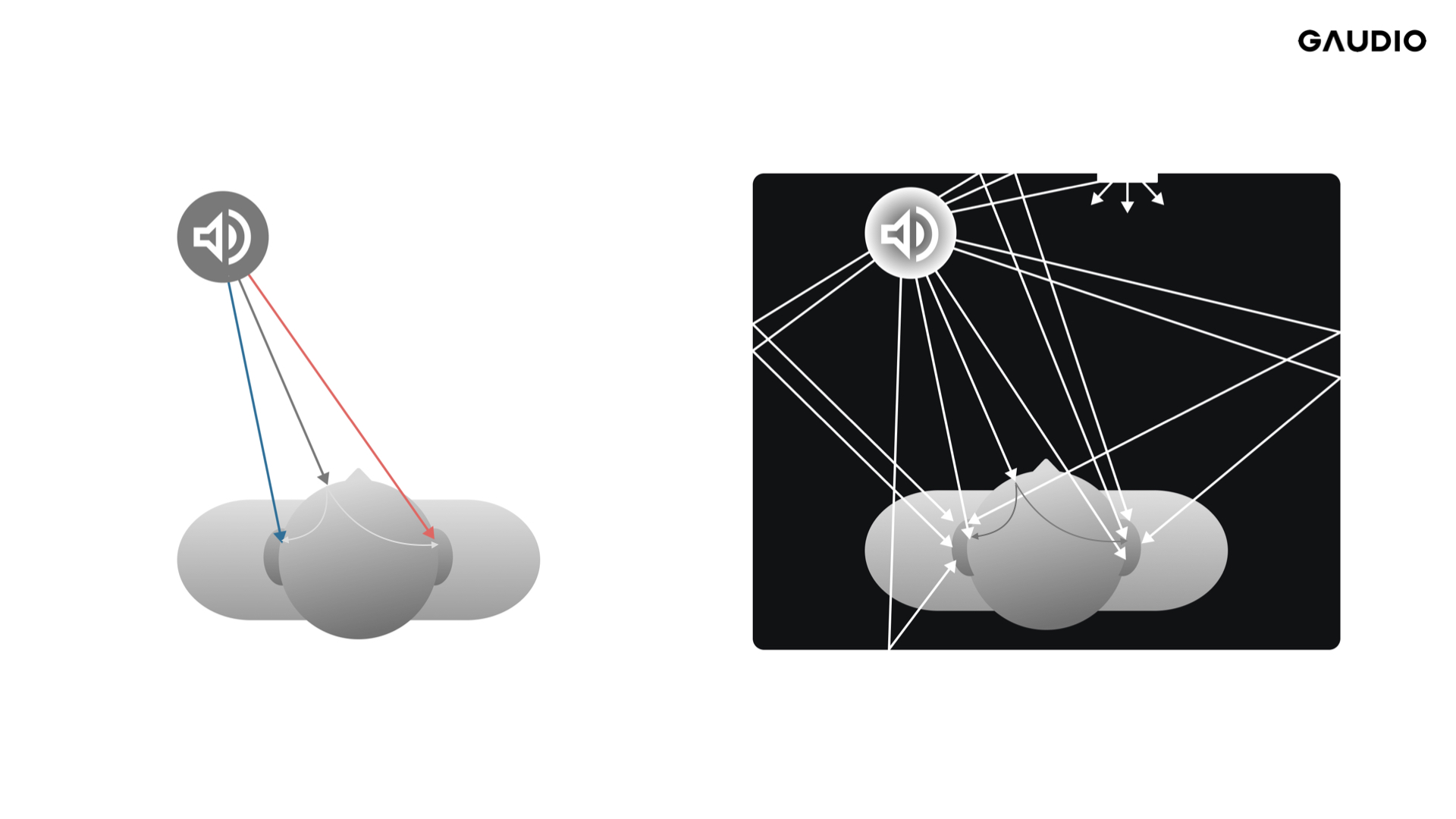
Figure 2 HRIR(좌) vs. BRIR(우)
(좌) 청취룸 특성 없는 음원과 청취자와의 관계 / (우) 청취룸 특성을 고려한 음원과 청취자와의 관계
Binaural Filter의 기본 개념은 특정 ‘위치’에 있는 음원으로부터 발생한 소리가 좌/우 측 귀에 들어오는 소리의 특성 변화를 정의하는 필터입니다. 따라서, 이 Binaural Filter는 거리, 수평각, 수직각에 대한 함수로 정의할 수 있죠. Binaural 필터를 정의함에 있어서 반사음 성분들에 의한 공간적 특성을 반영하였는지(BRIR) 아니면 음원과 사용자(의 양 귀)와의 관계만을 표현한 것인지(HRIR)에 따라서 달라지게 됩니다. BRIR의 경우 공간에서 발생하는 직접음 및 반사음까지 모두 Binaural Filter의 형태로 나타낸 것이고, HRIR은 반사음은 제외하고 직접음만을 고려한 Binaural Filter입니다. 당연히 BRIR 이 HRIR 보다 훨씬 긴 응답 길이를 갖고 있습니다.
일반적으로 Spatial audio는 HRIR보다는 BRIR을 사용하고 있어 본 글에서는 BRIR을 기준으로 설명 드립니다.
(a)
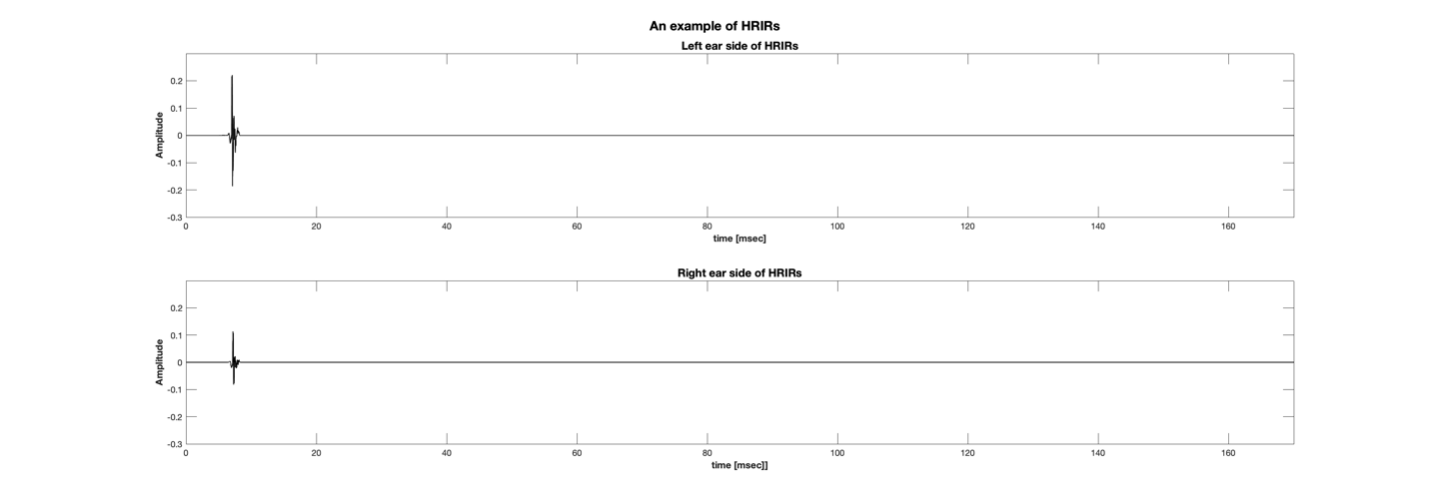
(b)
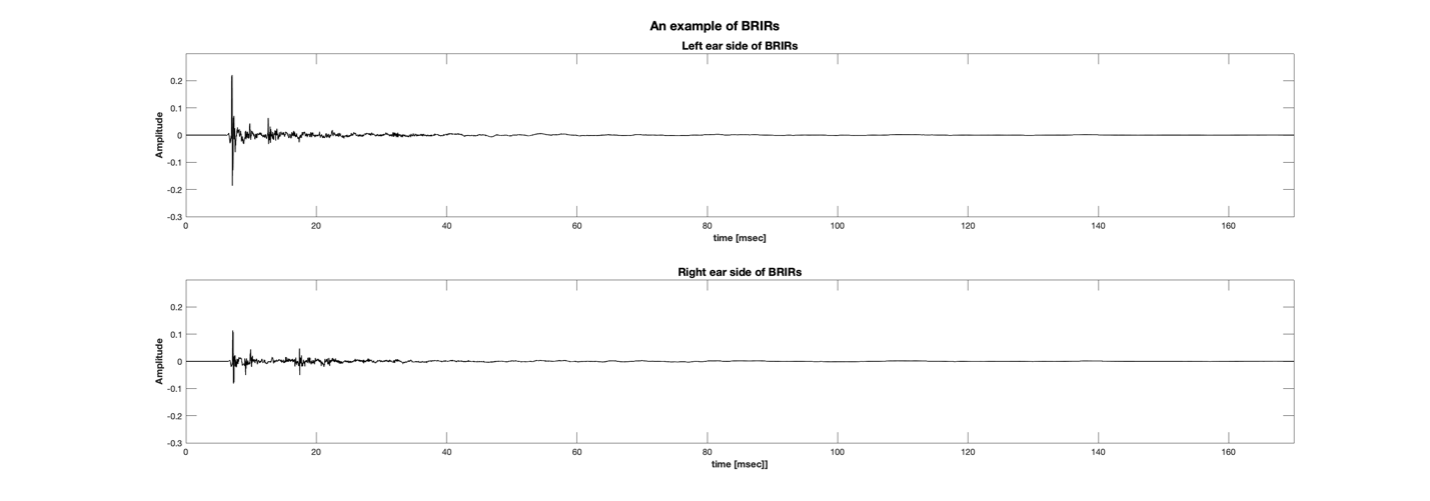
Figure 3 An Example of Impulse Responses of (a) HRIR and (b) BRIR
우선 두 개의 가상 음원 위치를 정할 필요가 있는데요. 이 때는 median plane(정중면; 좌우균등하게 나누는 면을 의미; 본 맥락에서는 사용자를 중심으로 좌우를 나누는 평면을 의미)을 기준으로 각각 다른 편에 속해 있는 두 개의 지점을 택하는 게 더 좋겠습니다. 이유는 이 측정 방법은 crosstalk cancellation 현상을 이용하여 측정하는 방법이기 때문입니다.
(앗, Crosstalk cancellation 현상이 무엇이냐고요? 이 글을 끝까지 읽다보면 자연스레 알 수 있답니다!)

Figure 4 An example of virtual speakers positions for M2S measurement
Figure 4처럼 median plane을 중심으로 서로 다른 편에 있는 두 개의 가상 음원의 위치가 결정되면, 각 음원으로부터 양쪽 귀까지의 전달함수, 즉 BRIR 을 두 세트를 측정할 수 있습니다. 이 세트를 [BRIR_LL, BRIR_LR], [BRIR_RL, BRIR_RR] 로 표시합니다. 각 세트에서 ‘_’뒤의 첫번째 알파벳은 음원의 위치(왼쪽 또는 오른쪽), 두번째 알파벳은 귀의 위치(왼쪽 귀 또는 오른쪽 귀)를 의미합니다. 즉, BRIR_LL은 왼쪽 스피커에서 발생한 소리가 공간 내에서 전파되다가 왼쪽 귀에 도달할 때까지의 충격응답을 의미하겠죠?
이렇게 BRIR세트를 구하면 어떤 단일 주파수 신호에 대해서 한쪽 귀에 들어오는 동측 음원으로부터 전달되는 신호(Ipsilateral Ear Input Signal)와 대측 음원으로부터 전달되는 신호 (Contralateral Ear Input Signal)의 크기 차이와 위상 차이를 구할 수 있습니다. 좀 더 풀어서 얘기하면, 왼쪽 스피커에서 왼쪽 귀로 재생되는 소리와 오른쪽 스피커에서 왼쪽귀로 재생되는 소리의 크기 차이와 위상 차이를 구할 수 있다는 이야기지요.
이러한 Ipsilateral Ear Input Signal과 Contralateral Ear Input Signal의 특정 주파수에 대한 크기 차이와 위상 차이를 계산해서 역함수 형태로 활용하여 오른쪽 가상 음원의 신호를 변경하면, 왼쪽 귀에는 crosstalk으로 인해 소리가 완전히 없어지거나 오른쪽에 비해 아주 작은 소리가 재생되도록 만들 수 있습니다. 거의 안 들리는 소리가 만들어 지는 것이죠. 이 크기 차이와 위상 차이는 BRIR의 주파수 영역에서의 표현인 BRTF(Binaural Room Transfer Function)의 크기 응답과 위상 응답으로부터 계산할 수도 있고, 특정 주파수를 이용하여 측정해서 획득할 수도 있습니다.
예를 들어 크기 차이와 위상 차이가 반영되지 않은 입력 신호는 아래와 같습니다.
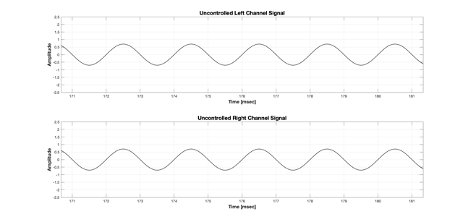
Figure 5 Uncontrolled input signal for left and right virtual speakers
위 Figure 5에서 위쪽이 가상 채널 중 왼쪽 채널의 입력 신호, 아래쪽이 가상 채널 중 오른쪽 채널의 입력 신호입니다. 완전히 동일한 신호입니다. 그런데 BRIR 로부터 왼쪽 채널과 오른쪽 채널로부터 왼쪽귀까지 해당 주파수의 크기차와 위상차를 구해서 최종 왼쪽 귀 입력 신호가 상쇄되도록 오른쪽 가상 채널 신호의 크기와 위상을 변경한다면? 입력 신호는 Figure 6과 같게 됩니다.
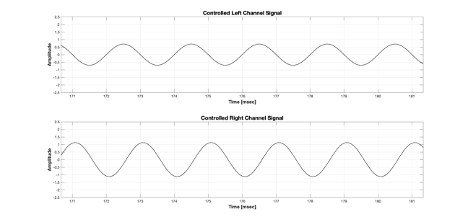
Figure 6 Controlled input signal for left and right virtual speakers
그럼, Figure 6과 같은 입력으로 재생했을 때 왼쪽귀의 입력 신호는 어떻게 될까요?
결과는 아래 Figure 7과 같습니다.
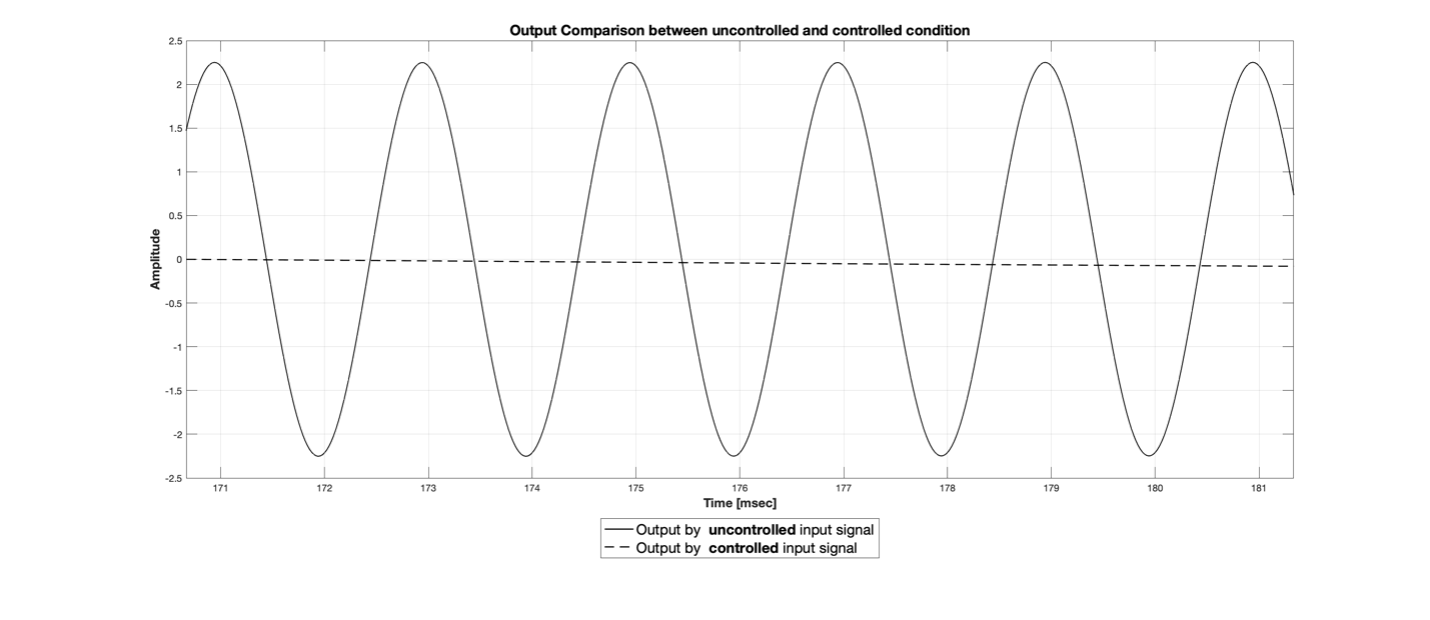
Figure 7 An example of left ear input signal for uncontrolled and controlled input signal
Figure 7에서 실선은 크기/위상차 조절을 하지 않고 양쪽 가상 채널에 동일한 신호를 렌더링 했을 때의 왼쪽 귀 입력 신호, 점선은 크기 위상차 조절한 신호를 오른쪽 가상 채널 신호에 반영했을 때 왼쪽 귀 입력 신호입니다. 확연하게 크기가 줄어든 것을 확인할 수 있는데요. 이러한 방법을 “crosstalk cancellation” 이라고 부릅니다. 크기/위상차를 절묘하게 변형시켜 동측에서 전달된 소리와 대측에서 전달된 소리가 상쇄되도록 만드는 방법을 의미하죠. 이 crosstalk cancellation 은 크기와 위상차가 딱 맞아떨어졌을 때 발생하고 둘 중 하나라도 조건에 맞지 않으면 오히려 출력 신호가 더 커지기도 합니다.
Figure 6과 같은 입력 신호를 렌더링 하면서 정면을 가만히 바라보고 있으면 왼쪽 귀로 들어오는 신호는 들리지 않거나 들린다고 하더라도 아주 작은 소리로 들리게 될 겁니다. BRIR에는 뒤쪽 reverb 에 해당하는 필터가 꼬리를 형성하고 있기 때문에 정확한 크기/위상차를 구했다고 하더라도 실제 오차가 다소 존재할 수 있습니다. 다만, 이 때 나는 소리가 제일 작은 크기의 소리인 것은 맞다고 말씀드릴 수 있어요.
[Measurement Method & Results]
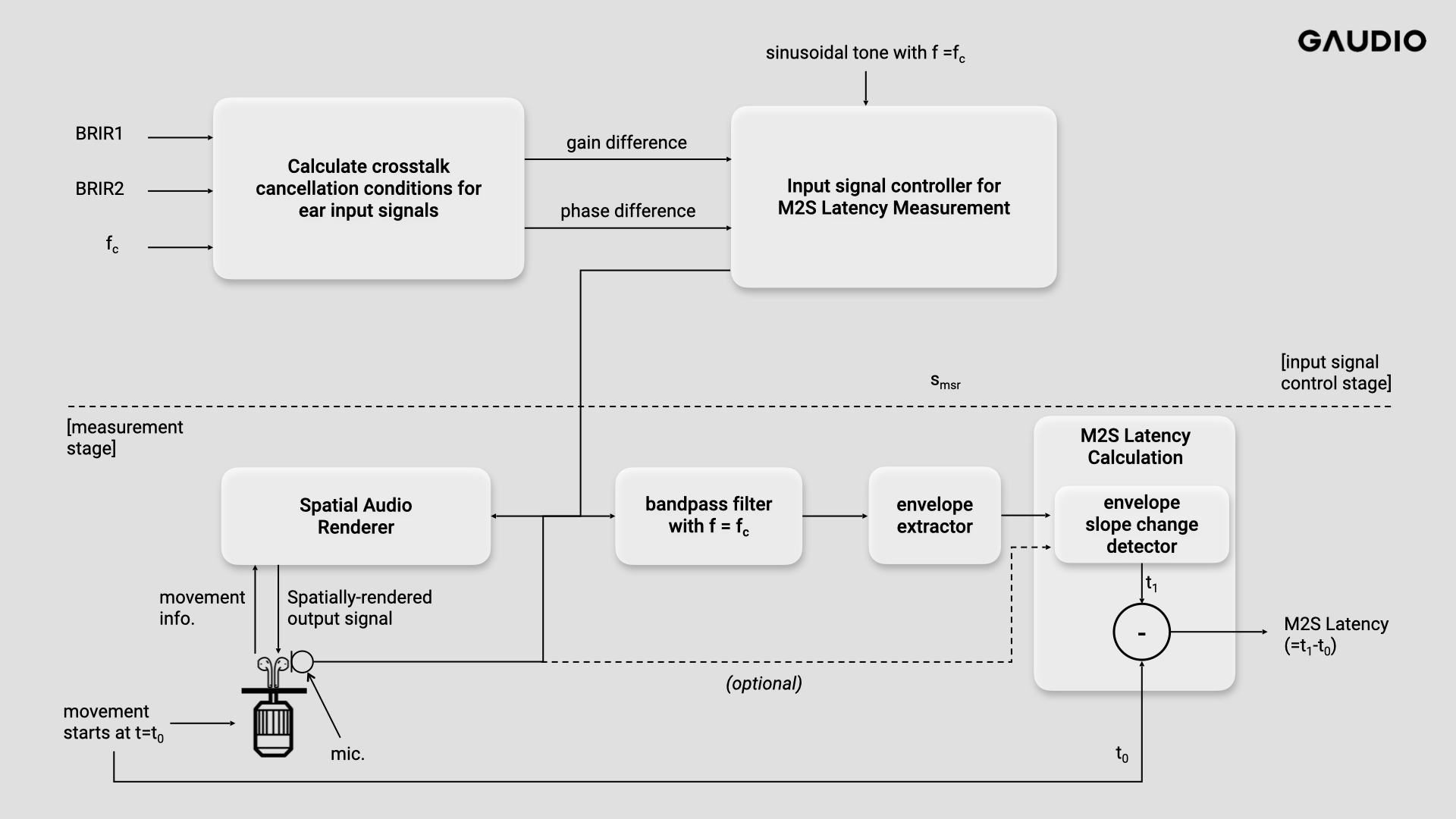
Figure 8 Block diagram for M2S measurement
Figure 8은 M2S(Motion-to-Sound) Latency를 측정하기 위한 과정을 그림으로 나타낸 것입니다. 앞서 설명한 내용은 M2S Latency를 측정하기 위한 입력 신호를 어떻게 생성할 수 있는지에 관한 것이고 위 그림의 [input signal control stage] 부분에 해당하겠네요. 그렇게 생성한 신호가 smsr입니다. 그럼 이제 실제 M2S Latency 측정을 해 보죠.
Spatial Audio Renderer에는 우리가 생성한 입력신호 smsr 이 입력되고, TWS(True Wireless Stereo)나 그 외의 IMU가 포함되어 있는 장치에서 움직임에 대한 정보를 전달받아, 그에 맞게 spatial audio rendering을 수행합니다.
우선 우리는 여기서 TWS에서 사용자의 움직임을 감지하여 해당 정보를 전달한다고 가정합니다. 사용자 움직임이 없는 경우, 출력된 바이노럴 신호의 왼쪽 또는 오른쪽 귀의 입력 신호는 crosstalk cancellation 때문에 소리가 나지 않거나 상대적으로 매우 작은 소리를 재생하고 있는 상황입니다. t=t0 순간에 모터 등을 이용하여 TWS를 회전시키면 TWS 는 그 움직임(실제로는 사용자의 움직임)을 감지하여 그에 맞는 movement 정보를 Spatial Audio Renderer로 전송하고, Spatial Audio Renderer는 그 정보에 맞게 렌더링을 하여 출력 신호를 생성하여 TWS를 이용해 재생하게 됩니다. 이렇게 재생된 소리를 획득하면 Crosstalk cancellation 조건이 깨지면서 렌더링 된 신호의 envelope의 변화를 볼 수 있고, 그로부터 M2S Latency를 측정할 수 있죠.
다만, 환경적 제약 때문에 Spatial Audio Renderer 의 출력신호를 직접 획득할 수 없는 상황이 있을 수도 있습니다. 그런 경우, external microphone 등을 통해 신호를 녹음하여 획득하여 사용합니다. 이 때 외부 잡음 등의 영향이 있을 수 있는데, 특정 주파수를 사용한 경우 대역통과필터 (Bandpass Filter) 를 이용하여 잡음을 제거할 수 있습니다. 아래 그림을 통해 조금 더 자세히 설명해 드릴게요.
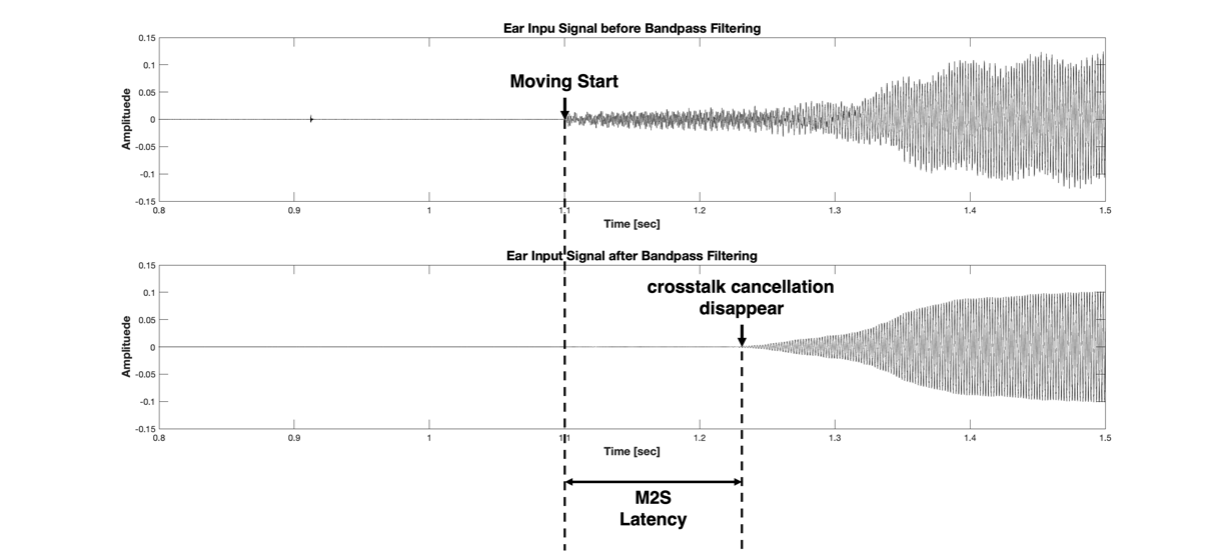
Figure 9 Recorded signal before(upper) and after(lower) bandpass filtering
Figure 9의 위쪽 그림이 원래 측정 신호입니다. Figure 9의 ‘Moving Start’ 시점이 Figure 8에서 t0에 해당합니다. 즉, ‘Moving Start’ 로 표시된 이전 구간은 정지되어 있는 상태입니다. 정지 상태에서는 Crosstalk Cancellation 덕분에 해당 방향의 Ear Input Signal은 상쇄되어 거의 들리지 않습니다. ‘Moving Start’ 순간부터 마이크로폰에는 모터가 동작하는 노이즈와 함께 실제 렌더링 되는 신호도 녹음이 될텐데요, 위쪽 그림에서는 렌더링 되는 신호는 크기가 작고 상대적으로 노이즈의 크기가 커서 언제부터 crosstalk cancellation 이 사라지는지 알 수가 없습니다. 이 실험에서 저희는 입력 신호로 500 Hz 의 pure tone 을 사용했습니다. 즉, 우리는 500Hz신호만 보면 되니, 위쪽 컬럼의 신호를 fc=500Hz 인 bandpass filter를 통과시키면 모터 구동음은 깨끗하게 없앨 수 있습니다. (윗 문단에서 언급한 대역통과필터를 이용한 잡음 제거) 그 결과가 Figure 9의 아래쪽 그림이 되는 것이고요. 움직이기 시작한 후부터 일정 시간이 지나면서부터 crosstalk cancellation 조건이 깨지면서 녹음되는 신호의 envelope이 커지는 걸 확인할 수 있습니다. 즉, crosstalk cancellation disappear 라고 표시된 시점이 Figure 8의 t1 에 해당하겠네요. 따라서, M2S Latency는 t1-t0 라고 계산할 수 있다는 것을 알 수 있습니다.
Envelope이 증가한 시점을 찾는 것은 여러가지 방법이 있겠습니다. 단순히 녹음된 신호의 샘플값이 커지는 구간을 찾을 수도 있긴 하겠습니다만, 너무 부정확한 방법이죠. 혹시나 perfect cancellation이 되지 않는다면 이 샘플값은 cancellation이 일어나고 있는 중에도 계속 변하게 될 것입니다. 그래서 개별 샘플 값을 이용하기 보다는 녹음된 신호를 일정 길이의 구간으로 나눈 후, 각 구간에 포함된 sample 값들의 variance를 구해서 사용하는 방법을 생각해볼 수 있습니다. Envelope 을 구하기 위해 variance 값을 계산한다면 각 구간의 길이를 선택하는 것이 중요합니다. 이 시간 구간을 짧게 잡으면 시간 영역에서 time precision은 높아질 수 있습니다만, 입력 신호 주파수의 주기보다는 길어야 합니다. 즉, 각 구간의 최소 길이는 입력 신호 주파수의 주기보다는 길어야 합니다. 위의 예시에서는 500Hz를 입력 신호로 사용하였고, 따라서 적어도 우리는 envelope의 변화량을 얻기 위해서는 2ms 이상의 시간 구간을 잡아야 한다는 의미죠. 즉, 500Hz 신호를 입력으로 사용한 경우 최대 precision은 2 ms 입니다. 해상도를 높이고 싶으면 더 높은 주파수의 입력 신호를 사용해도 괜찮습니다. 다만 너무 높은 주파수의 입력 신호를 사용할 경우 필터로부터 계산할 수 있는 크기/위상차의 오차 범위가 다소 높아질 수 있는 위험도 있으니 조심해야 할 필요는 있겠지요! 그 이외에 측정된 신호로부터 sparse envelope 을 추출하고 envelope의 실제 slope 를 계산해서 slope 가 급격히 변하는 지점을 기준으로 M2S Latency를 측정할 수도 있습니다. 측정 환경과 녹음 결과에 따라 이는 선택적으로 변경해서 사용할 수 있겠습니다.
결국 Figure 9에서처럼 원래 녹음된 신호와 fc=500Hz로 Bandpass filtering 된 신호를 기반으로 우리는 M2S Latency를 측정할 수 있습니다. 이 latency는 앞서 도면으로 그렸던 모든 관련된 정보가 오가는 과정에서 발생하는 latency가 포함된 값입니다. 따라서 이 latency가 실제 사용자가 경험하게 되는 latency가 됩니다.
[그래서 실제로 Latency를 측정해보니…]
요즘 출시되는 TWS 들은 공간음향 기능이 탑재되어 소리에 공간감을 더함과 동시에 사용자의 고개 움직임 등에 반응하는 렌더링 기능들을 제공하죠. 아시다시피 가우디오랩은 공간음향 기술의 원조이자 최고의 기술력을 자랑하는 회사인만큼, 각 제품들이 사용자의 움직임에 얼마나 빨리 반응해 좋은 퀄리티를 제공할 수 있을지를 파악하고자 여러 제조사의 TWS를 대상으로 M2S Latency 를 측정하였습니다. 측정치는 최소 10회의 측정을 기반으로 평균값을 구한 것이고, 따라서 그 표준 편차도 함께 기재해 봤습니다.
위에서 설명드린 측정방법을 활용해 다양한 TWS의 M2S Latency 를 측정해보았더니, 예시값은 아래 표 1과 같음을 알 수 있었습니다.
<Table 1 M2S latencies for different TWS [unit: ms]>
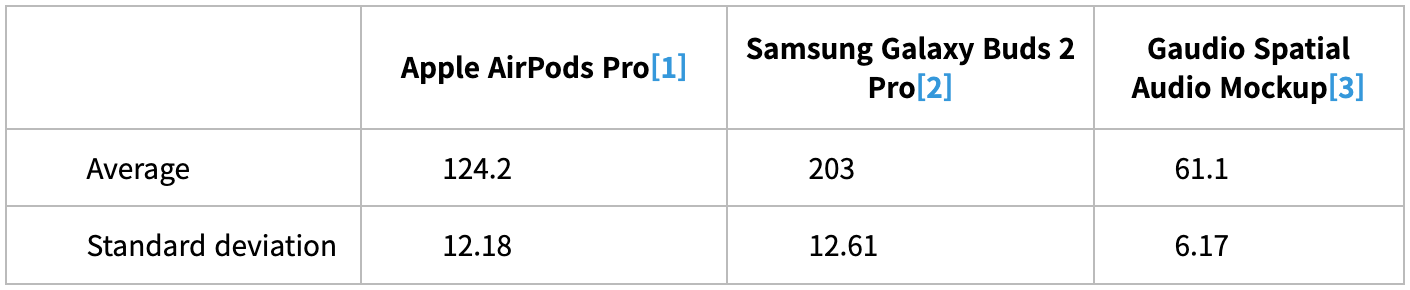
측정 결과는 놀라웠는데요. 가우디오랩의 기술이 (아직은 Mock-up 수준이라고 해도) 월등히 낮은 Motion-to-Sound Latency를 기록하고 있었습니다! 그 이유는 가우디오랩의 Spatial Audio Mock-up이 세계 최고의 Spatial Audio렌더링 최적화 기술로 TWS 위에서 구동되는 방식을 바탕으로 만들어졌고, 이는 기존의 다른 주요 TWS들이 채택하여 사용하고 있는 스마트폰 렌더링 방식에 반드시 필요한 Bluetooth Communication Latency를 제거할 수 있기에 얻어진 결과라고 말씀드릴 수 있겠습니다.
글을 시작하면서, Spatial Audio의 전체적인 품질은 공간과 방향의 특성을 렌더링하는 음질 뿐만 아니라 사용자의 움직임으로부터 렌더링되어 소리가 재현되는 데에 소요되는 시간 (motion-to-sound latency)에 따라 결정된다고 말씀드렸던 것을 기억하시나요?
공간음향의 품질을 높여주는 Motion-to-sound latency를 측정하는 방법을 설명 드리고자 시작한 이 글을 통해 가우디오랩의 기술력이 압도적인 뛰어난 수치들을 기록하고 있음까지 확인할 수 있었습니다.
Latency가 최고 수준인 것은 알겠는데, 그렇다면 과연 음질은 어떻게 되는지 궁금하실텐데요. 다음 글에서는 latency에 이어 놀라운 결과를 보여준 음질 평가 실험과 그 결과에 대해서 사운드 샘플과 함께 공개할 예정이니 Stay tuned~!
아! 가우디오랩이 2023년 CES에서 혁신상 2관왕을 차지했다더니, 역시 그럴만한 결과네요! ㅎㅎㅎ
------
[1] iPhone 11과 Airpods Pro로 구성된 렌더링에 대한 측정치임. 실제 렌더링은 iPhone에서 일어나고Phone-TWS간 통신 지연에 의한 지연이 큰 구조
[2] Galaxy Flip4와 Galaxy Buds 2 Pro로 구성된 렌더링에 대한 측정치임. 실제 렌더링은 Galaxy에서 일어나고Phone-TWS간 통신 지연에 의한 지연이 큰 구조
[3] iPhone11 과 가우디오랩에서 제작한TWS Chipset 위에 구현하여, 통신 지연을 제거한 목업의 측정 결과. iPhone은 소스 기기로 사용되고 Spatial Audio Rendering은 TWS 에서 수행.


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
