Integrating Audio AI SDK with WebRTC (1): A Look Inside WebRTC's Audio Pipeline
Integrating Audio AI SDK with WebRTC (1): A Look Inside WebRTC's Audio Pipeline
(Writer: Jack Noh)
Curious About WebRTC?
The MDN documentation describes WebRTC (Web Real-Time Communication) in the following manner.
(It should be noted that the MDN documentation is essentially a standard reference that anyone engaged in web development will inevitably encounter.)
WebRTC (Web Real-Time Communication) is a technology enabling web applications and sites to capture and freely stream audio or video media between browsers, eliminating the need for an intermediary. In addition, it permits the exchange of arbitrary data. The series of standards composing WebRTC facilitate end-to-end data sharing and video conferencing, all without requiring plugins or the installation of third-party software.
To simplify, WebRTC is a technology that allows your browser to communicate in real-time with only an internet connection, which eliminates the need to install any extra software. Services exemplifying the use of WebRTC include Google Meet, a video conferencing service, and Discord, a voice communication service. (This technology also gained substantial attention during the outbreak of Covid-19!) As an open-source project and web standard, WebRTC's source code can also be accessed and modified via the following link.
Understanding WebRTC's Audio Pipeline
WebRTC is a comprehensive multimedia technology, encompassing diverse technologies such as audio, video, and data streams. In this article, I aim to delve into aspects related to WebRTC's audio technology.
If you've had experience using a WebRTC-enabled video conferencing or voice call web application (e.g., Google Meet), you might be intrigued to understand how the Audio pipeline is structured. The Audio pipeline can be separated into two distinct Streams. Firstly, 1) the Stream of voice data captured from the microphone device and transmitted to the other party, and concurrently, 2) the Stream that receives the other party's voice data and outputs it via the speaker. These are respectively referred to as the Near-end Stream (sending the microphone input signal to the other party) and the Far-end Stream (outputting the audio data received from the other party through the speaker). We'll take a closer look at each Stream, which consists of five steps, in the sections below.
1) Near-end Stream (Transmitting Microphone Input Signal to the Receiver)
- Audio signals are received from the microphone device. (ADM, Audio Device Module)
- Enhancements are applied to the input audio signal to augment call quality. (APM, Audio Processing Module)
- If there are other audio signals (e.g., file streams) to be concurrently transmitted, they are integrated using an Audio Mixer.
- The audio signal is subsequently encoded. (ACM, Audio Coding Module)
- The signal is converted into RTP packets and dispatched through UDP Transport. (Sending)
2) Far-end Stream (Projecting the Received Audio Data from the Sender through the Speaker)
- Audio data in the form of RTP packets is received from the connected peers (multiple Peers). (Receiving)
- Each RTP packet is decoded. (ACM, Audio Coding Module)
- The decoded multiple streams are merged into a single stream by an Audio Mixer.
- Enhancements are applied to the output audio signal to augment call quality. (APM, Audio Processing Module)
- The audio signal is eventually outputted through the speaker device. (ADM, Audio Device Module)
The names of the modules responsible for each stage of the process are noted in brackets on the right in the preceding descriptions. WebRTC exhibits this level of modularization for each process.
Here are more detailed explanations for each module:
- ADM (Audio Device Module): This interfaces with the input/output hardware domain, facilitating the capture/render of audio signals. It's implemented using APIs tailored to the respective platform (Windows, MacOS, etc.).
- APM (Audio Processing Module): This comprises a set of audio signal processing filters designed to boost call quality. It's primarily employed on the client end.
- Audio Mixer: This consolidates multiple audio streams.
- ACM (Audio Coding Module): This executes the encoding/decoding of audio for transmission/reception.
The aforementioned process can be visualized as shown in the following diagram.
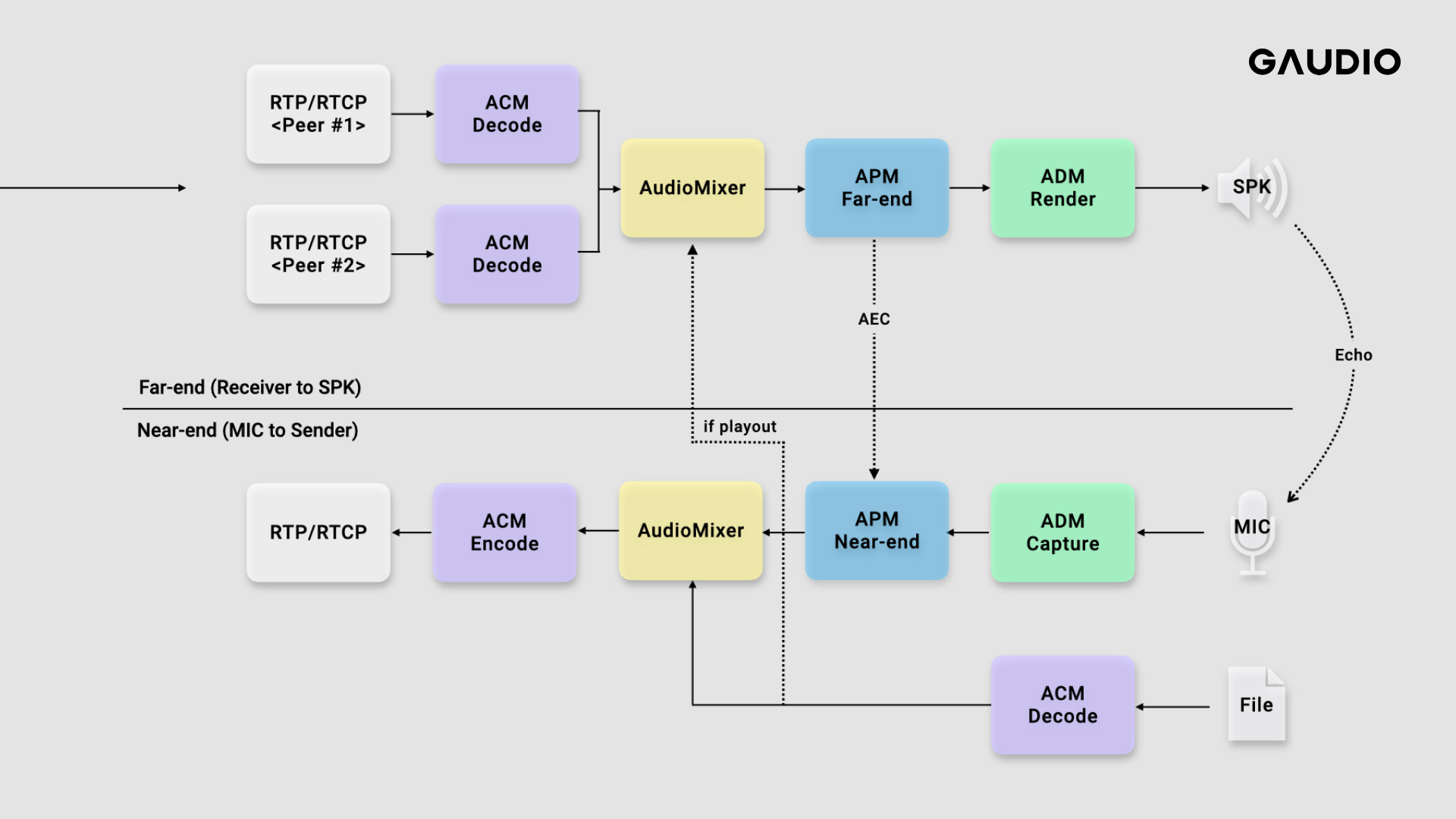
As previously described, the audio pipeline in WebRTC is notably modular, with its functionalities neatly divided.
Enhancing WebRTC Audio Quality with Gaudio SDK
Gaudio Lab houses several impressive and practical audio SDKs, such as GSA (Gaudio Spatial Audio), GSMO (Gaudio Sol Music One), and LM1 (a volume normalization standard based on TTA). The idea of developing applications or services using these SDKs, thus delivering superior auditory experiences to users, is indeed captivating.
(Did you know?) Gaudio Lab boasts an SDK that fits seamlessly with WebRTC – The GSEP-LD, a noise reduction feature that operates on AI principles. Interestingly, it offers real-time functionality with minimal computational demand (and provides top-tier performance on a global scale!)
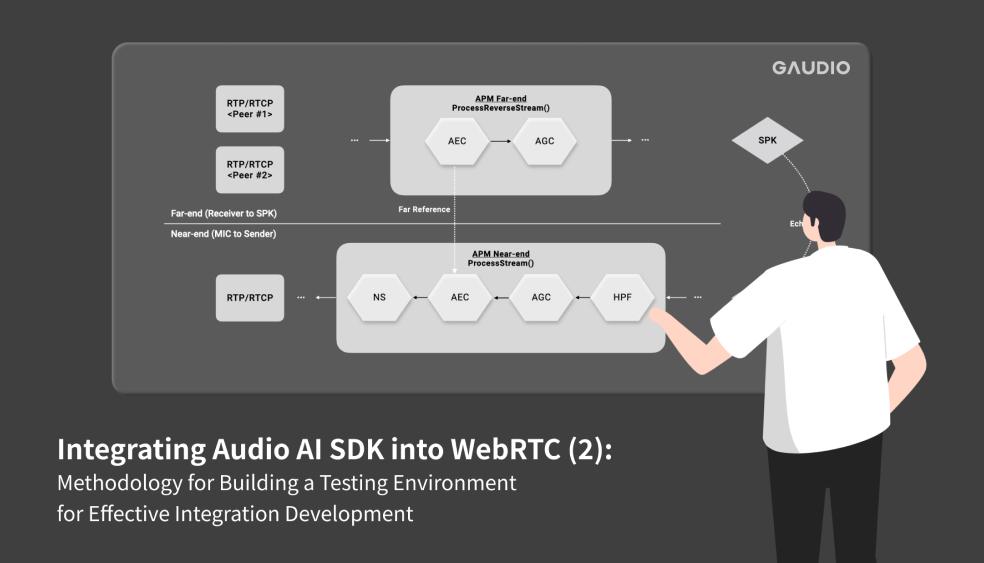
We often endure discomfort due to ambient noise while conducting video conferences. To alleviate such noise-related concerns, WebRTC incorporates a noise suppression filter rooted in signal processing. (As a point of interest, WebRTC already contains filters beyond noise suppression to improve call quality!) This noise suppression filter forms part of the previously mentioned APM (Audio Processing Module).
Imagine the potential improvements if we replaced the conventional signal processing-based noise suppression filter with Gaudio Lab's AI-driven noise suppression filter. However, despite the eagerness to instantly substitute the existing noise suppression filter with GSEP-LD, it is crucial to proceed with caution. Attempting hasty integration (or replacement) in such a complex, large-scale project can generate complications, as raised by the following considerations:
- Does the original performance of GSEP-LD measure up well? → It is important to verify the quality of the original performance.
- Could there be any side effects with the existing signal processing-based filters? → It is advisable to check the effects while managing other filters in WebRTC.
- Does the optimal point of integration align with the location of the existing noise reduction filter? → Various points of integration should be tested.
- Can performance be guaranteed across diverse user environments? → This requires a wide range of experimental data and consideration of different platform-specific settings.
If one dives headfirst into the project solely driven by enthusiasm, they might find themselves overwhelmed by the questions mentioned earlier, causing effective integration to become increasingly challenging. To circumvent this, the primary step entails building a 'robust testing environment'. The larger the project, with its many interconnected technologies, the greater the emphasis on this requirement.
However, establishing a robust testing environment is not an easy undertaking. In this article, I have discussed the audio technology of WebRTC. In the next article, I will share my experience in establishing a solid testing environment within WebRTC with relative ease. This allowed me to significantly boost my confidence in the performance as I was able to integrate GSEP-LD into the WebRTC audio pipeline.

Our audio technologies support various devices and platforms.
