DCASE 2023: Gaudio Lab paved the way as always in ‘AI Olympics for Sound Generation’
Introduction to DCASE
DCASE is an esteemed international data challenge in the field of acoustics, with prestigious institutions from around the globe participating.
In the world's inaugural AI Sound Generation Challenge, Gaudio Lab not only pioneered the Foley Sound Synthesis sector of the DCASE (an acronym for Detection and Classification of Acoustic Scenes and Events) Challenge but also managed to secure second place overall, despite participating light-heartedly.
Launched in 2013, the DCASE competition, marking its ninth year now, holds a stature equivalent to the 'Olympics' in the field of Sound AI. Coinciding with the advent of the AI era, a sound generation category was introduced for the first time in this edition of the competition. The contest saw participation from not just global corporations like Gaudio Lab, Google, Sony, Nokia, and Hitachi, but also renowned global universities such as Carnegie Mellon University, University of Tokyo, Seoul National University, and KAIST. This led to a stage brimming with cutting-edge competition in the Sound AI sector. With 123 teams applying across seven projects, a total of 428 submissions were received, highlighting the intensity of the competition.
World's First AI Sound Generation Challenge: Foley Sound Synthesis Challenge
The 'Foley Sound Synthesis' task, a new entrant in the field of generative AI, garnered substantial interest this year. This task specifically involved the generation of sounds belonging to specific categories (like cars, sneezes, etc.), utilizing AI technology and data. Given our extensive experience in this sector, Gaudio Lab served as the organizer, setting the direction for the task. Despite our nonchalant participation, we accomplished the feat of securing second place. Notably, in the evaluation of 'sound diversity', which is considered an essential metric from a commercialization perspective, Gaudio Lab received scores significantly higher than our direct competition.
[Figure 1] Overview and Organizers of the DCASE 2023 Foley Sound Synthesis Challenge
Remarks on DCASE 2023
You might be curious as to how Gaudio Lab, a small Korean startup, was able to organize this competition and even stand tall on the podium among renowned global corporations and world-class universities. This success can be attributed to Gaudio Lab's foresight and early beginnings in the field of generative AI research and development, coupled with the relentless efforts of our AI researchers working diligently behind the scenes. Now that we've boasted enough, let's turn the spotlight to the real heroes.
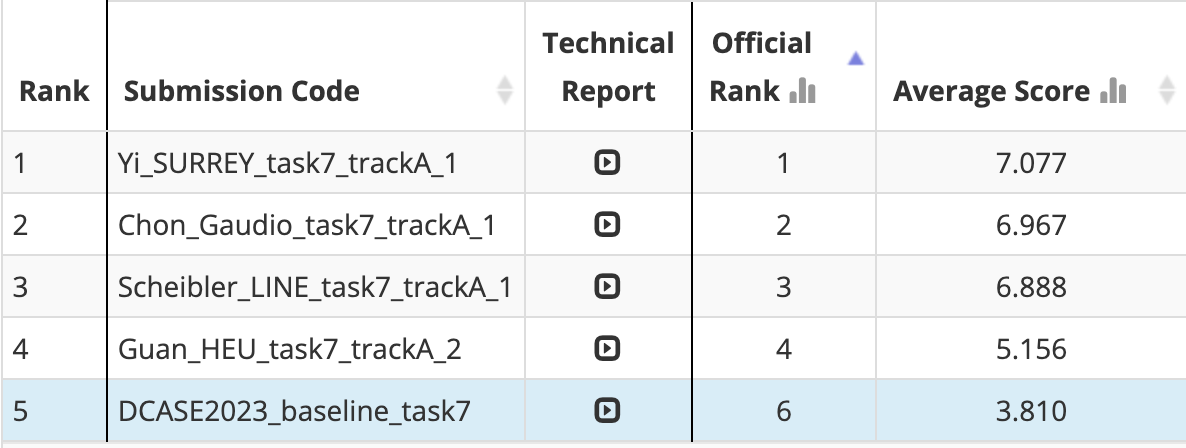
[Figure 2] DCASE Ranking Announcement Screen, 'Chon_Gaudio' presents the results submitted by Gaudio Lab.
What does DCASE mean to Gaudio Lab?
Ben Chon: Gaudio Lab embarked on a journey of researching and developing sound generation AI with the ambitious goal of reproducing all sounds in the world as early as 2021, well before ChatGPT became a sensation (see [Figure 4] for reference). After extensive research, we achieved Category-to-Sound generation in June 2022, a concept akin to this DCASE challenge. Since then, we've dedicated ourselves to the more ambitious objectives of (arbitrary) Text-to-Sound and (arbitrary) Image-to-Sound research to attain a commercial-level implementation outside of the lab, where significant strides have already been made. We ultimately envision our Video-to-Sound generation model to become an indispensable solution in every scenario where sound is needed - not only in traditional media such as movies and games but also in next-generation media platforms like the metaverse, by creating an apt sound for any form of input.
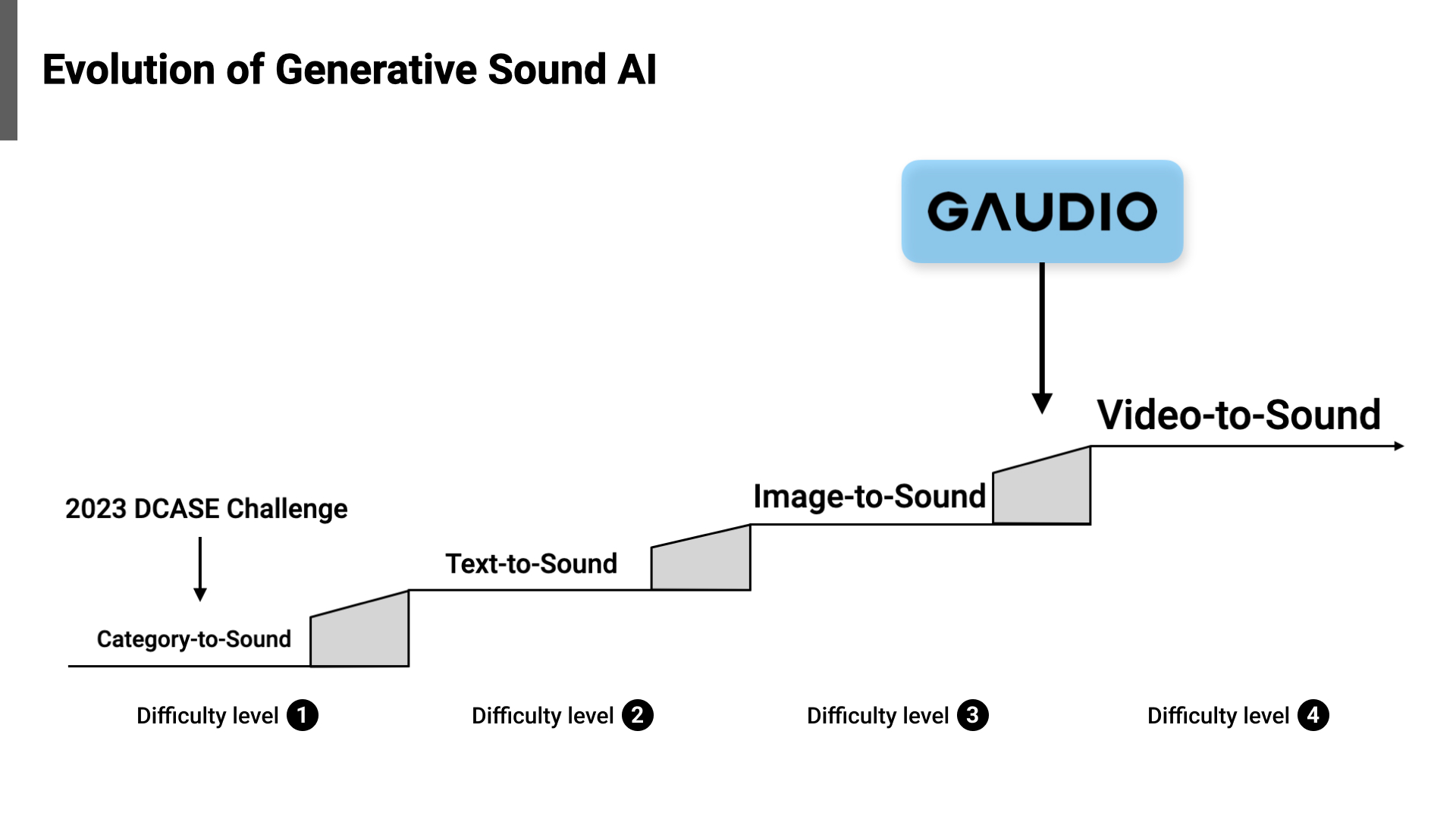
[Figure 3] Evolution of Generative Sound AI, Gaudio Lab is at Difficulty Level 3
Compared to Gaudio Lab's AI, whose goal is to generate all conceivable sounds, the Category-to-Sound model as mandated by DCASE is somewhat restrictive, narrowing the scope of sound generation to a handful of categories. As a result, this category seemed to be somewhat of a small playground for Gaudio Lab's technological prowess. In this competition, over 30 technological entries were submitted.
There were moments of solitude, questioning if we were the only ones spearheading this niche. However, being the organizers of the competition allowed us to stimulate research in this field, and in the process, reaffirm the global stature of our technology, which has been a meaningful experience. As we are at the forefront of commercialization, we intend to sustain our leadership in this market by learning from the research outcomes of other participants.
[Figure 4] The cover of the materials from the kickoff meeting for SSG (Sound Studio Gaudio), Gaudio Lab's sound generation AI project, a truly legendary beginning
What were the most significant challenges in preparing for DCASE?
Keunwoo Choi : As Gaudio Lab was the principal organization in this field, the most challenging aspect was balancing between the roles of an international competition organizer and Gaudio Lab's Research Director. Given that Foley Sound Synthesis was a challenge introduced in DCASE for the first time, we endeavored, as organizers, to set a positive benchmark by curating a fair and scholarly consequential competition.
Concurrently, in my capacity as Gaudio Lab's Research Director, I had to orchestrate and implement a comprehensive research plan while dividing limited computational resources. This task felt analogous to resolving an intricate puzzle. To allocate human and GPU resources efficiently, I developed detailed charts to optimize workload distribution. In retrospect, following the successful completion of the competition, the experience seems invaluable.
Rio Oh : Although the entire process was complex, training the LM (Language Model) based model was particularly difficult. The overall process was strenuous, mainly because the outcomes didn't always match the amount of effort we put in.
What was the most memorable moment during the preparation for DCASE?
Manuel Kang : The most memorable moment was when our AI successfully generated a realistic animal sound for the first time in June 2022. I was very proud to see our initial model, which started with no sound production, gradually improve to this point.
Monica Lee : Indeed, the moment our model produced a genuine animal sound for the first time remains unforgettable. When I played the artificially generated puppy sound at home, my pet dog, Sabine, reacted by barking and appearing confused. It seems we effortlessly passed the puppy Turing test! (Haha)
Rio Oh : Our generation model underwent numerous updates During the preparation process. Each time the model operated as planned without any glitches, it was immensely satisfying. Among these moments, I remember most vividly when we could control aspects like background noise and recording environment to our liking.
Devin Moon : Performing optimizations to capture subtle nuances in sound through prompt engineering was exciting. I distinctly remember when we generated the sound of quickly running on a creaky wooden floor within a resonant space. The generated sound was so realistic that it was still hard to distinguish from the actual sound.
What sets Gaudio Lab's generative AI apart?
Ben Chon : A key distinction of Gaudio Lab's AI lies in its capabilities that surpass the original parameters of the Category-to-Sound task. The AI can generate virtually any sound, extending from Text-to-Sound to Image-to-Sound. In simpler terms, while our model has the potential to create a vast array of sounds, it was constrained to generate sounds from certain categories in the context of the competition. This situation is similar to a marathon runner participating in a 100-meter sprint.
In reality, our AI can synthesize nearly every conceivable sound, ranging from various animal noises to the ambient sounds of an African savannah teeming with hundreds of species. Moreover, its ability to isolate and generate the sound of a single object without noise interference offers significant advantages when the technology is used directly in content production for films and games.
Keunwoo Choi : In order to develop a high-performing and versatile model, we dedicated significant effort from the outset to data collection, arguably the most crucial aspect of AI development. We systematically gathered all possible data worldwide and supplemented gaps in information with the assistance of AI tools, such as ChatGPT. Our aim was to accumulate the best quality data possible. A key initiative in our data collection strategy was the acquisition of 'Wavelab,' a top-tier film sound studio in South Korea. This step enabled us to secure high-quality data. Furthermore, our generative model's design sets Gaudio Lab's AI apart. Our model deviates from traditional AI models that specialize in music or voice, and is designed to create a wide spectrum of sounds or audio signals.
Would you mind sharing your thoughts on behalf of your team about this achievement?
Ben Chon: Gaudio Lab has transcended the constraints of the DCASE task to develop a Text-to-Sound model capable of producing virtually any sound. Recognition from DCASE, which operates within a select range of sound categories, is a strong testament to the maturity of Gaudio Lab's AI development capabilities, bringing us closer to a truly 'universal' sound model.
Our indirect validation of world-class quality across diverse sound categories, some not even covered by DCASE, gives us greater confidence for future research. I believe our team has achieved something truly remarkable. Kudos to all the researchers at Gaudio Lab for their hard work!
Keunwoo Choi : It is extremely rewarding to see the fruits of our continuous research and development in the vast field of generative audio AI. DCASE held its first generative audio challenge, which was relatively straightforward in terms of problem definition. However, our system was already performing well with far more intricate text prompts. I hope we can further develop and commercialize this technology, which possesses infinite possibilities, to cause a significant ripple effect in the audio industry.
Could you please share your future aspirations or vision?
Ben Chon : We believe it's crucial for Gaudio Lab's generative AI to secure practical use cases in the real industry, in addition to making an impact in the academic realm. Having participated in DCASE, our generative AI has grown beyond the Text-to-Sound capability to effectively handle Image-to-Sound tasks. We're also considering expanding our scope to include Video-to-Sound. With technology advancing at an astonishing pace, it's time for us to evolve our focus towards impacting people's lives directly by integrating our technology in real-world industry applications. In fact, our efforts are already bearing fruit, with ongoing discussions about potential collaborations with companies in forward-looking sectors such as film production and the metaverse.
I am eager to ensure that Gaudio Lab leads both technological advancement and commercialization, aiming for a future where we stand at the heart of global sound production. We appreciate your continued interest and support for Gaudio Lab's AI technology!
In closing,
I am truly delighted to announce that the relentless efforts of the Gaudio Lab researchers, who have silently navigated uncharted territories, can now be proudly showcased on the global stage. Until we realize our vision of "All sounds in the world originating from Gaudio Lab," we ask for your continued interest and support for Gaudio Lab's AI technology.
Our audio technologies support various devices and platforms.
