Is there AI that creates sounds? : Sound and Generative AI
The Surge of Generative AI Brought by ChatGPT
(Writer: Keunwoo Choi)
The excitement surrounding generative AI is palpable, as evidenced by its widespread integration like ChatGPT into our daily lives. It feels like we're witnessing the dawn of a new era, similar to the early days of smartphones. The enthusiasm for generative AI, initially sparked by ChatGPT, has since spread to other domains, including art and music.
Generative AI in the Field of Sound
Sound is no exception; Generative AI has made significant advances, particularly in AI-based voice synthesis and music composition. However, when we consider the sounds that make up our everyday environments, voices and music are only a small part of the equation. It's the little sounds like the clicking of a keyboard, the sound of someone breathing, or the hum of a refrigerator that truly shapes our auditory experiences. Without these sounds, even the most finely crafted voices and music would fail to capture the essence of our sonic world fully.
Despite their significance, we have yet to see an AI that can generate the multitude of sounds that make up our sonic environment, which we'll refer to as 'Foley Sounds' for the sake of explanation. The reason for this is quite simple: it's dauntingly challenging. To generate every sound in the world, an AI must have access to data representing every sound in the world. This requires the consideration of numerous variables, making the task incredibly complex.
Knowing the difficulties involved, Gaudio Lab has taken up the challenge of generating all of the sounds in the world. In fact, we began developing an AI capable of doing so even before generative AI became a hot topic in 2021.
Without further ado, let's listen to the demo they have created.
AI-Generated Sounds vs. Real Sounds
How many right answers did you get?
As you could hear in the demo, the quality of AI-generated sound now easily surpasses the common expectation.
Finally, It is time to uncover how these incredibly realistic sounds are generated.
Gaudio Lab generates sounds through AI
Visualizing Sounds: Waveform Graph
Before we can delve into the process of generating sounds with AI, it's essential to understand how sounds are represented. You may have come across images like this before:
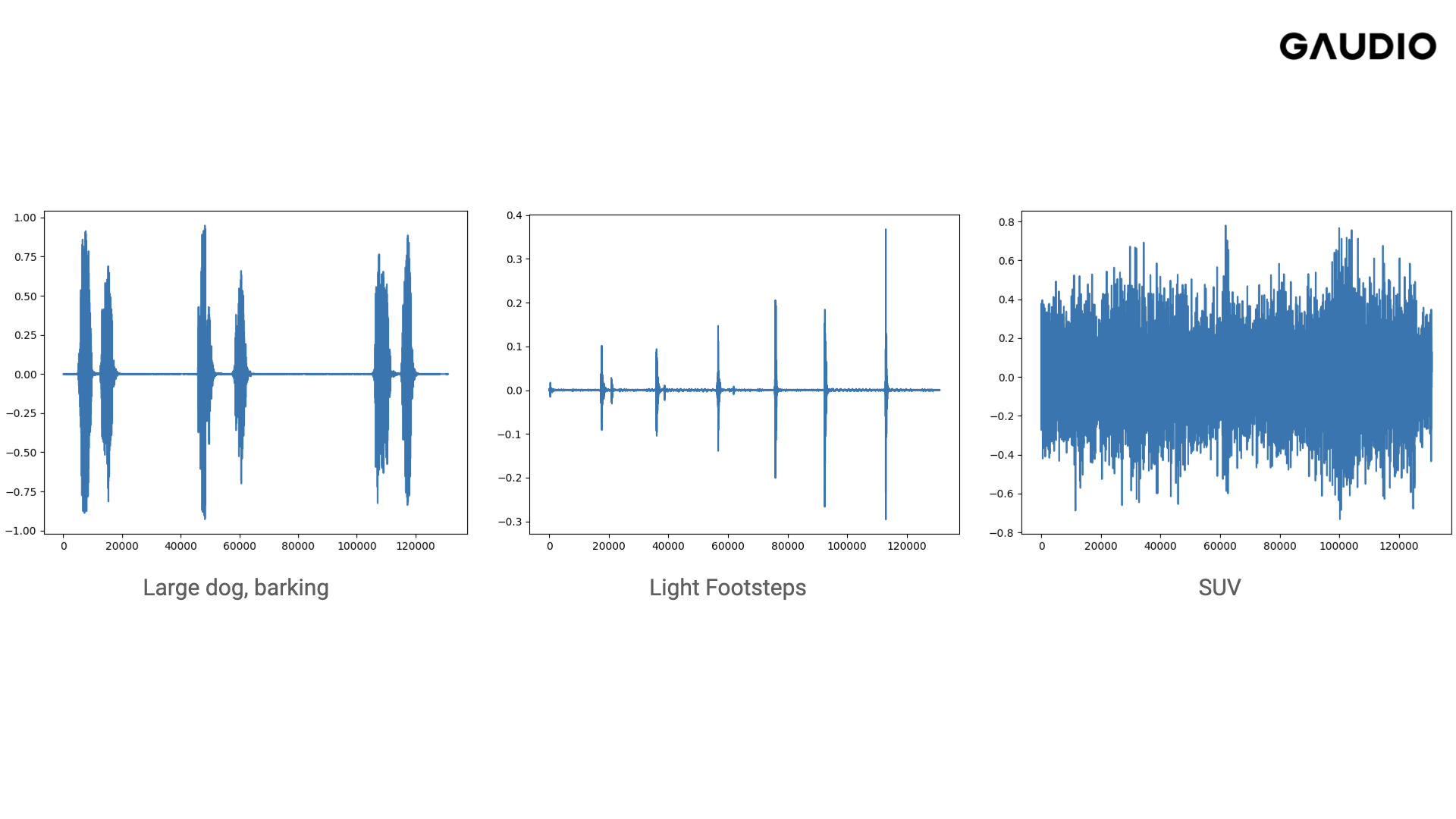
The graph above illustrates the waveform of sound over time, which enables us to estimate when and how loud a sound occurs, but not its specific characteristics.
Visualizing Sounds: Spectrogram
The spectrogram was developed to overcome these limitations.
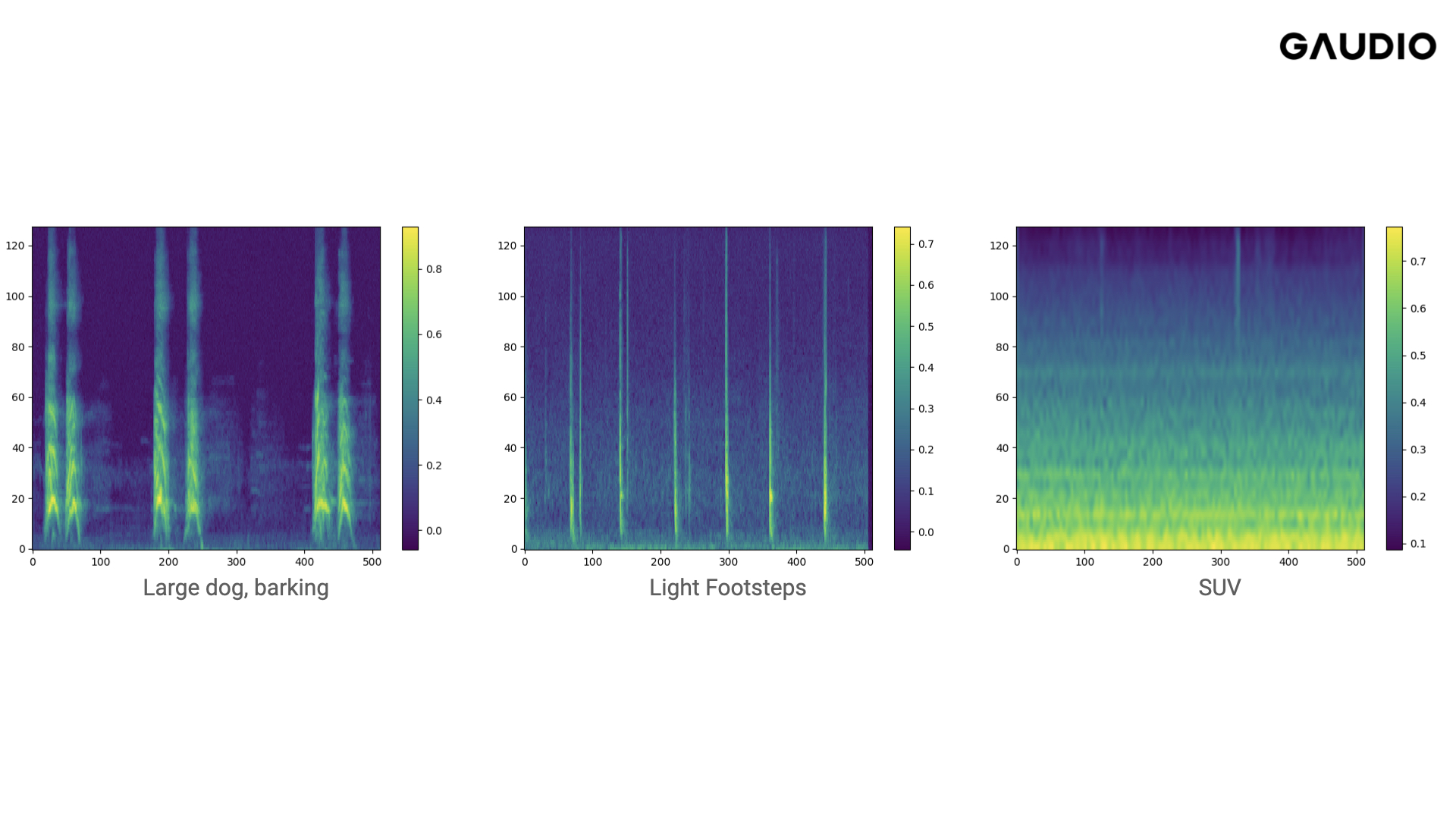
At first glance, the spectrogram already appears to contain more information than the previous graph.
The x-axis represents time, the y-axis represents frequency, and the color of each pixel indicates the amplitude of the sound. Essentially, a spectrogram can be seen as the DNA of sound, containing all the information about a particular sound. Therefore, if a tool can convert a spectrogram into an audio signal, creating sound is equivalent to generating an image. This simplifies many tasks, as it allows for the use of the similar diffusion-based image generation algorithm employed by OpenAI's DALL-E 2.
Now, do you see why we explained the spectrogram? Let's take a closer look at the actual process of creating sound using AI.
Creating Sound with AI: The Process Explained

Step 1: Generating Small Spectrograms from Text Input
The first step in creating sound with AI involves processing the input that describes the desired sound. For example, when given a text input such as "Roaring thunder" the diffusion model generates a small spectrogram from random noise. This spectrogram is made up of a 16x64 pixel image, representing 16 frequency bands and 64 frames. Although it may appear too small to be useful, even a small spectrogram can contain significant information about a sound.
Step 2: Super Resolution
The image then undergoes a 'Super Resolution' phase, where the diffusion model iteratively improves the resolution through multiple stages, resulting in a clear and detailed spectrogram as shown earlier.
Step 3: Vocoder
This final step involves converting the spectrogram into an audio signal using a vocoder. However, most market-available vocoders are designed to work with voice signals, making them unsuitable for a wide range of sounds. To address this limitation, Gaudio Lab developed its own vocoder, which has achieved world-class performance levels. Furthermore, Gaudio Lab plans to release this vocoder as an open-source tool in the first half of 2023.
Gaudio Lab’s World-class Sound Generation AI
What makes developing sound-generation AI challenging?
While the process may appear straightforward at first glance, producing realistic sounds with AI requires addressing numerous challenges. In fact, AI is only a tool, and solving the actual problem demands the expertise of individuals in the field of audio.
Handling and managing large amounts of audio data is one of the biggest challenges in creating AI-generated sound. For instance, the size of Gaudio Lab's training data is approximately 10TB, corresponding to about 10,000 hours of audio. This requires a high level of expertise to collect and manage the data, as well as the ability to efficiently load the audio data for training, in order to minimize I/O overhead. In comparison, ChatGPT's training data is known to be around 570GB, and ImageNet, a dataset that has driven the progress of deep learning in computer vision, is only about 150 GB.
Evaluating AI models for audio is also difficult because it requires listening to the generated audio in its entirety, which is time-consuming and can be influenced by the listening environment. This makes it challenging to determine the quality of the generated audio objectively.
When it comes to sound generation AI, expertly developed AI models produce better results.
Having a team of experts in audio engineering is undoubtedly an advantage for Gaudio Lab. Our expertise and knowledge of audio help to ensure that the AI models generate high-quality and realistic sounds. Additionally, our experience in audio research at globally renowned companies allows Gaudio Lab to stay up-to-date with the latest audio technologies and trends. Their participation in the listening evaluation process ensures that the generated audio meets high standards, making Gaudio Lab's sound generation AI a unique and valuable asset.
The Evolution of Sound Generation AI
Gaudio Lab's ultimate goal is to contribute to the development of the metaverse by filling it with sound using their AI technology. While the current performance of their sound generation AI is impressive, they acknowledge the need for further development to capture all the sounds in the world.
Participation in the DCASE 2023 Challenge
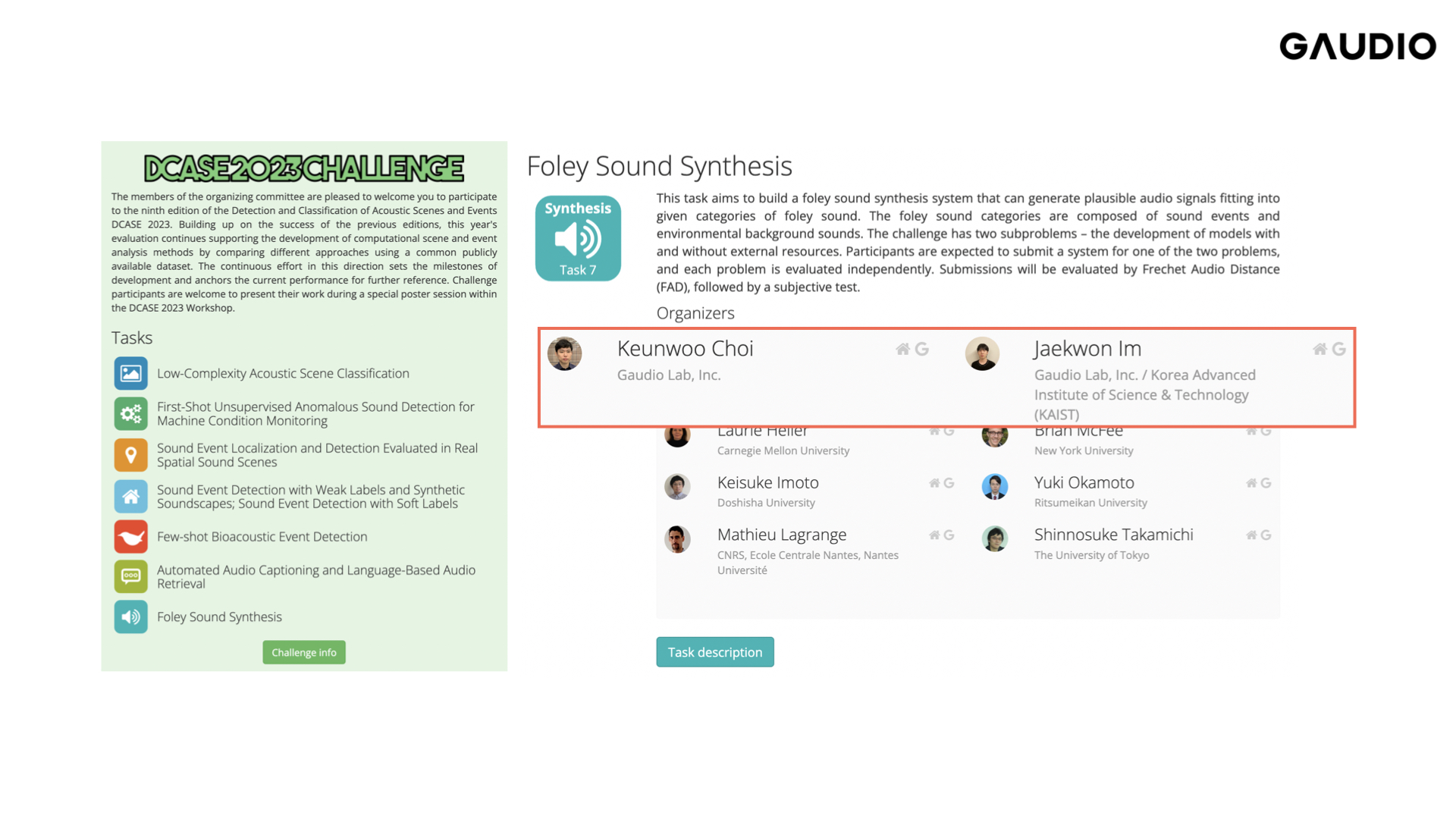
Participating in DCASE is a great opportunity for Gaudio Lab to showcase its exceptional sound generation AI and compete with other top audio research teams from around the world. The evaluation process in DCASE will likely involve objective metrics such as signal-to-noise ratio, perceptual evaluation of speech quality, and speech intelligibility, as well as subjective evaluations where human listeners will provide feedback on the generated sounds. The results of DCASE will provide valuable insights and feedback for Gaudio Lab to continue improving its AI models and enhance the quality of the generated sounds. Please wish Gaudio Lab the best of luck in DCASE and look forward to hearing positive updates about our progress.
We'll be releasing AI-generated sounds soon, so stay tuned!


Our audio technologies support various devices and platforms.
